词频统计后的结果输出形式
当前代码实现了对于文本数据词频的统计,但是结果输出不太美观,不好使用
现有代码:

现在的结果形式:

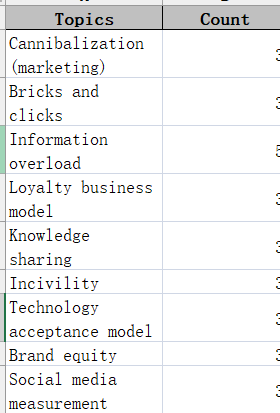
想在现有代码的基础上,实现结果输出到Excel,两列,词与出现的频数一一对应,目标结果如图:
(其他较为美观、方便使用的数据格式也可以,不一定要输出到Excel)
import xlwt
n = 1
dic = {'张三': 2, '李四': 3, '王五': 2}
wb = xlwt.Workbook()
sheet = wb.add_sheet('Sheet1')
sheet.write(0, 0, 'Topics')
sheet.write(0, 1, 'Count')
for i in dic:
sheet.write(n, 0, i)
sheet.write(n, 1, dic[i])
n += 1
wb.save('test.xls')
s=open("a.txt","r",encoding='utf-8').read()
i=0
s1=s.lower()
ls=list(s1.replace(',',' ').replace('.',' ').split())
lss=[]
for ss in ls:
lss.append((ls.count(ss),ss))
lss.sort(reverse=True)
lss=[(ss,n) for (n,ss) in lss]
dic_lss=dict(lss)
for key in dic_lss.keys():
print("{} : {}".format(key,dic_lss[key]))
