搭建hadoop集群时,格式化失败
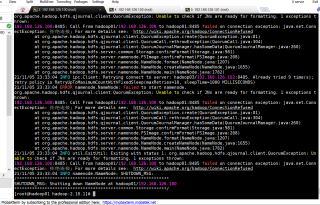
在第一次格式化成功后,主节点有namenode,但是从节点没有namenode,然后再一次进行格式化,就无法正常格式化。显示错误
哈哈,我之前也遇到类似的问题,先启动dfs start-dfs.sh,在格式化,我前两天也上传一个Hadoop集群,可以看看
正常格式化成功如图:
第一次没有格式化成功,再第二次格式化就会出现异常,出现:

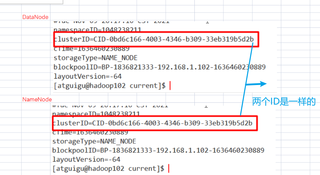
datanode和namenode的ID不一样
这时候就需要:
1.关闭所有服务(重启linux--目的就是为了关闭集群)
2.删除每个节点上的data和logs (hadoop的根目录下)
3.删除/tmp下的内容 : sudo rm -rf /tmp/*
4.重新格式化
然后就可以了