Python中pandas怎么实现分组去重统计和求和
原数据:
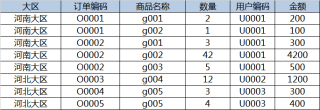
想要的结果:

sql实现逻辑:
select
大区,
count(distinct 用户编码) as 用户数,
count(distinct 订单编码) as 订单数,
sum(数量) as 数量,
sum(金额) as 金额
from order_table
group by 大区
我现在想到的是Python方法是分别计算,然后进行组合:
df1 = order_table.groupby('大区')['数量','金额'].sum()
df2 = order_table.groupby('大区')['用户编码','订单编码'].unique()
result = pd.merge( df1 , df2 ,how = 'left' ,on = '大区')
现在的问题Python有没有更简单的方法,直接用一个语句实现
result = order_able.groupby('大区').agg({'数量': 'sum', '金额': 'sum', '用户编码': 'unique', '订单编码': 'unique'})
import pandas as pd
import pandasql as ps
d = {'大区': ['河南大区', '河南大区', '河南大区', '河南大区', '河南大区', '河北大区', '河北大区', '河北大区'],
'订单编码': ['O0001','O0001','O0002','O0002','O0002','O0003','O0004','O0005', ],
'商品名称': ['g001','g002','g001', 'g002','g003','g004','g005','g005',],
'数量': [2, 1, 3, 42, 5, 12, 3, 4],
'用户编码': ['U0001', 'U0001', 'U0001', 'U0001', 'U0001', 'U0002','U0003','U0003', ],
'金额': [200, 100, 300, 42000, 500, 1200, 300, 400],
}
df = pd.DataFrame(d)
print(df)
fun = lambda q: ps.sqldf(q, globals())
q = """select
大区,
count(distinct 用户编码) as 用户数,
count(distinct 订单编码) as 订单数,
sum(数量) as 数量,
sum(金额) as 金额
from df
group by 大区
"""
res = fun(q)
print(res)
groupby 后面可以用agg吧