Pandas 重复索引中的不同列合并
具体问题放在图片里了 想知道怎么能再不影响其他行数据的情况下完成图片里的需求 已经转换成Dataframe格式了 在数据处理中用过 drop_duplicates()完全去重的方法 只是下面这种数据的情况比较特殊
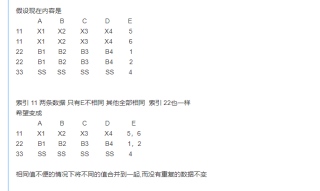
尝试一下使用如下代码处理:
import pandas as pd
df=pd.DataFrame({'A':['X1','X1','B1','B1','SS'],'B':['X2','X2','B2','B2','SS'],'C':[5,6,1,2,4]},index=['11','11','22','22','33'])
df=df.reset_index().groupby(['index','A','B'])['C'].apply(lambda x:','.join(map(str,x))).to_frame().reset_index().set_index('index')
#df=df.rename_axis([''],axis=0)
print(df)
如对你有帮助,请采纳。点击我回答右上角【采纳】按钮。