Python的etree.HTML解析不了网页是怎么回事(代码附上)?
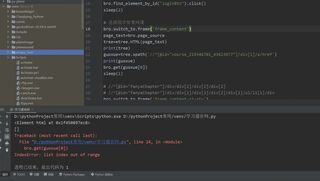

我用selenium解析网页,再将内容放到etree.HTML里面,结果只有一个元素的列表,这是什么情况?我打印了page_text,里面确实是网页源码,可放到etree.HTML里面却不行了。更离谱的是十分钟前还可以的,我完善了一下代码就这样了。对了,我也导入了相关模块了。自从自学Python以来,莫名其妙的问题越来越多,大多数都是我从没想过会出问题的地方报了错。
index out of range 很常见的错误 下标超出范围了,你已经打印出来了 你的guoxue 是空列表 你访问guoxue[0]肯定报错
至于为什么是空列表 需要进一步分析 如果你觉得 etree有问题 可以再导入一个库 解析一下 你获取的 page_source看看