Python Ajax爬虫请求url与原网址一样,预览有数据,但是爬不到
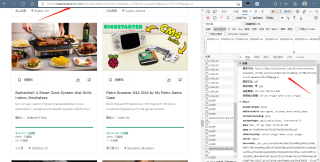
复制请求url进入和原网址一样
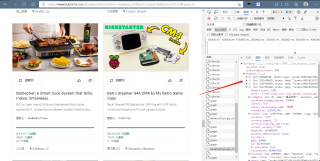
预览这里就是要的数据,但是不知道怎么爬下来
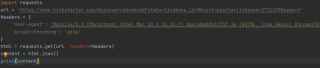
这是爬取页面的代码
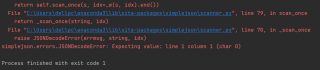
它还显示了不是json格式
这种该怎么爬取,求大家帮忙解答。
反扒可能判断了Referer来源,一起加上试试。还有ajax请求会附带X-Requested-With: XMLHttpRequest请求头,最好一起带上
1.先用print(html.text)或保存到本地,看一下返回的源代码及数据,如有数据项,使用re正则结合json,loads,dumps对数据解析。
2.如果没有数据项内容,说明是动态渲染加载,要么找到数据加载的接口去请求获取,要么用selenium