为什么SQL子查询结果没有加GROUP BY还能按分组结果显示
CREATE TABLE t_book (FId int(11) NOT NULL,FName varchar(50) DEFAULT NULL,FYearPublished int(11) DEFAULT NULL,FCategoryId int(11) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
-- Records of t_book
INSERT INTO t_book VALUES ('1', 'About J2EE', '2005', '4');
INSERT INTO t_book VALUES ('2', 'Learning Hibernate', '2003', '4');
INSERT INTO t_book VALUES ('3', 'Two Cites', '1999', '1');
INSERT INTO t_book VALUES ('4', 'Jane Eyre', '2001', '1');
INSERT INTO t_book VALUES ('5', 'Oliver Twist', '2002', '1');
INSERT INTO t_book VALUES ('6', 'History of China', '1982', '2');
INSERT INTO t_book VALUES ('7', 'History of England', '1860', '2');
INSERT INTO t_book VALUES ('8', 'History of America', '1700', '2');
INSERT INTO t_book VALUES ('9', 'History of The World', '2008', '2');
INSERT INTO t_book VALUES ('10', 'Atom', '1930', '3');
INSERT INTO t_book VALUES ('11', 'RELATIVITY', '1945', '3');
INSERT INTO t_book VALUES ('12', 'Computer', '1970', '3');
INSERT INTO t_book VALUES ('13', 'Astronomy', '1971', '3');
INSERT INTO t_book VALUES ('14', 'How To Singing', '1771', '5');
INSERT INTO t_book VALUES ('15', 'DaoDeJing', '2001', '6');
INSERT INTO t_book VALUES ('16', 'Obedience to Authority', '1995', '6');
CREATE TABLE t_category (FId int(11) NOT NULL,FName varchar(50) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
-- Records of t_category
INSERT INTO t_category VALUES ('1', 'Story');
INSERT INTO t_category VALUES ('2', 'History');
INSERT INTO t_category VALUES ('3', 'Theory');
INSERT INTO t_category VALUES ('4', 'Technology');
INSERT INTO t_category VALUES ('5', 'Art');
INSERT INTO t_category VALUES ('6', 'Philosophy');
任务:查询出每种类目的 类目名称、类目id,最晚的出版年份
想要得到的结果类似下图
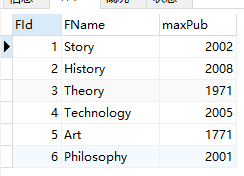
原文提供了两种写法
第一种:
select c.*,A.maxPub
from t_category c
left join (
select b.FCategoryId cid ,max(b.fyearpublished) maxPub from t_book b group by b.FCategoryId)A
on c.fid=A.cid
第二种
select c.fid,c.FName,(select max(b.FYearPublished) from t_book b where b.FCategoryId=c.FId) maxPub from t_category c
第二种仅按照代码来理解,子查询中得到的结果,难道不是用条件b.FCategoryId=c.FId连接起来的所有类目中最晚的发布年份吗?为什么第二种写法 子查询中没有加GROUP BY 还能运行出来呢?

第二种仅按照代码来理解,子查询中得到的结果,难道不是用条件b.FCategoryId=c.FId连接起来的所有类目中最晚的发布年份吗?为什么第二种写法 子查询中没有加GROUP BY 还能运行出来呢?
针对你这个问题我大概解释一下啊,子查询select max(b.FYearPublished) from t_book b where b.FCategoryId=c.FId的意思是已经过滤后的的结果再进行max函数取最大值,过滤条件就是当类目已经确定是某一个的时候,所以不用再group by。
举例说明,如不加子查询的结果为
1 Story
2 History
3 Theory
4 Technology
5 Art
6 Philosophy
增加子查询后,
针对第一行,子查询就等于select max(b.FYearPublished) from t_book b where b.FCategoryId=1
结果为:
1 Story 2002
2 History
3 Theory
4 Technology
5 Art
6 Philosophy
第二行为select max(b.FYearPublished) from t_book b where b.FCategoryId=2,结果为:
1 Story 2002
2 History 2008
3 Theory
4 Technology
5 Art
6 Philosophy
依次类推
就是
1 Story 2002
2 History 2008
3 Theory 1971
4 Technology 2005
5 Art 1771
6 Philosophy 2001