【python】网站原html文档和requests+beautifulsoup得到的不一致
网站html部分截图: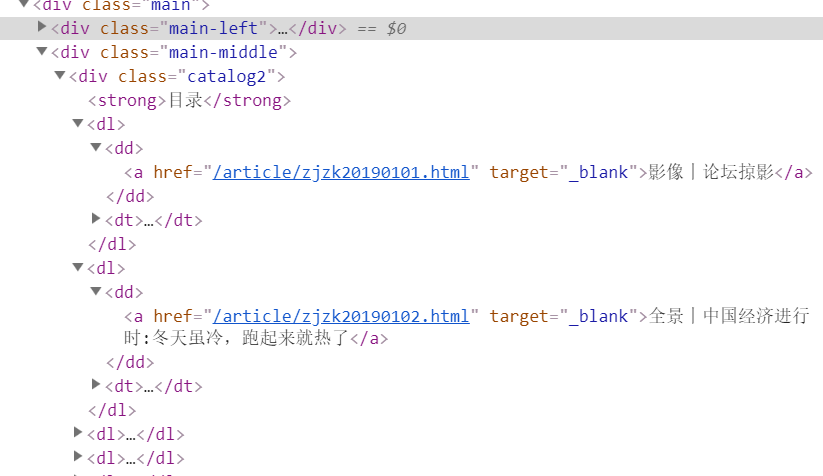
想爬取目录下的标题(例如截图中的“影像 论坛撩影”)
在shell中找标签过程如下:
>>> from bs4 import BeautifulSoup
>>> import requests
>>> url='http://www.qikan.com.cn/magdetails/4A07226A-70B4-41A8-B61A-3A45A4E09FEC/2019/1.html'
>>> r=requests.get(url)
>>> r.encoding
'utf-8'
>>> soup=BeautifulSoup(r.text,'html.parser')
>>> soup.find("div",attrs={"class":"catalog2"})
<div class="catalog2">
<strong>目录</strong>
<dl>
<dd><a href="/article/zjzk20190101.html" target="_blank">影像丨</a></dd></dl></div>
发现 div class="catalog2" 标签下的内容和原网站不符
于是将 soup.prettify() 输出到txt中,发现输出如下(截取部分):
<div class="catalog2">
<strong>
目录
</strong>
<dl>
<dd>
<a href="/article/zjzk20190101.html" target="_blank">
影像丨
</a>
</dd>
</dl>
</div>
</div>
</div>
</div>
</div>
</div>
</div>
</form>
</body>
</html>
论坛掠影
<dt>
<span style="display: ">
<img src="http://img.qikan.com.cn/qkimages/zjzk/zjzk201901/72_72/zjzk20190101-1-s.jpg"/>
</span>
第十七届中国经济论坛在人民日报社举行。 2018年12月29日,由人民日报社指导,《中国经济周刊》、中国信通院、工信部工业互联网产业联盟共同主办的第十七届中国经济论坛在人民日报社举行。来自政商学界的460 多位嘉宾出席论坛。 人民日报社副总...
</dt>
<dl>
想询问为什么标签位置与原网页的不一致,应该怎么解决?
找到解决方案了!
用BeautifulSoup的时候不要用‘html.parser’来解析,用‘lxml’就可以了
有大佬能解答下这两个的区别么……
代码应该是没问题,理论上应该不会出现不一致的情况,可能是网页html中本身就有不止一个catalog2的标签,或者你没有完全把图中的源代码展开

em你是想爬去所有目录嘛...应该获取他们的父标签,然后循环遍历取出子标签