Python的Scrapy模块;解释一下?
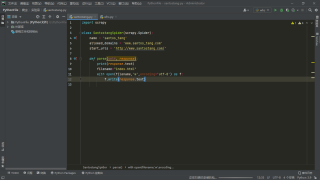
这是一段别人(陌生人)的代码,当初她问我这哪里错了的时候我忘记问这段代码准备用来做什么了,现在啊,找不到那个人了,就想问一问,不知道有没有会scrapy的能解释一下这是准备干嘛?反正呢,我是不明白这个
我想,如果我知道了原作者的意图,说不定我还能补全这个代码,也算是给我这种刚学的人练练手
问:原作者写的这段代码是用来做什么的?
这个只是爬虫的Spider编写
啥也没做 没有入口 都运行不了
顶多实现下面:
import requests
url = 'https://www.santostang.com/'
response = requests.get(url)
print(response.text)
with open('index.html','w',encoding='utf-8') as f:
f.write(response.text)
这是爬虫主模块部分吧,看样子的打算爬上面那个网站的内容,后面是把爬取的数据保存一个html文件?
是个基于spider类的爬虫脚本,指定了爬虫名、允许爬取的域名列表和初始url列表,下面那个方法是把响应文本保存为本地的html文件