这个应该怎么改才能抓取详情信息
import requests
from bs4 import BeautifulSoup
import pandas as pd
def get_data(url):
headers={'User-Agent':"Mozilla/5.0 (Windows NT 10.0; Win64; x64) \
AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.114 Safari/537.36"}
try:
r = requests.get(url, headers=headers)
r.encoding = 'GBK'
r.raise_for_status()
return r.text
except requests.HTTPError as e:
print(e)
print("HTTPError")
except requests.RequestException as e:
print(e)
except:
print("Unknown Error !")
def parse_data(html):
soup = BeautifulSoup(html, "html.parser")
soup
tbList =soup.find_all('table', attrs = {'class': 'tbspan'})
for item in tbList:
p=item.stripped_strings
for i in p:
print(i)
#print(2)
movie = []
link = item.b.find_all('a')[1]
name = link["title"]
url = 'https://www.dy2018.com' + link["href"]
try:
temp = soup.BeautifulSoup(data(url), 'html.parser')
tbody = temp.find_all('tbody')
for i in tbody:
download = i.a.text
if 'magnet:?xt=urn:btih' in download:
movie.append(name)
movie.append(url)
movie.append(download)
#print (movie)
movie.append(movie)
break
except Exception as e:
print(e)
return movie
def save_data(data):
filename = 'tt.csv'
dataframe = pd.DataFrame(data)
dataframe.to_csv(filename,mode='a',index=False, sep=',')
def main():
for page in range(1,2):
print('正在爬取:第' + str(page) + '页......')
if page == 1:
index = 'index'
else:
index = 'index_' + str(page)
url = 'https://www.dy2018.com/html/bikan/'+ index +'.html'
html = get_data(url)
movies = parse_data(html)
save_data(movies)
print('第' + str(page) + '页完成!')
if __name__ == '__main__':
print('爬虫启动成功!')
main()
print('爬虫执行完毕!')
爬取的电影天堂但是保存不到本地
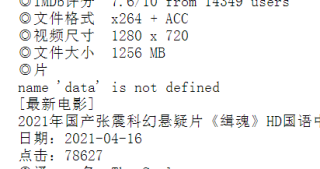
name = link["title"],,link没有title这个属性,应该是定位问题吧
如果对你有帮助,可以点击我这个回答右上方的【采纳】按钮,给我个采纳吗,谢谢
