pandas怎么合并某字段有重复项的表?
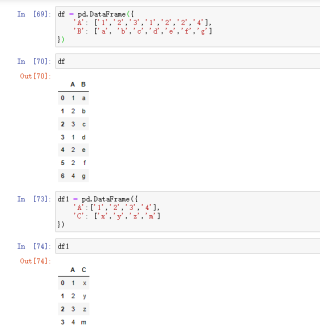
怎么拼接成下图这样?
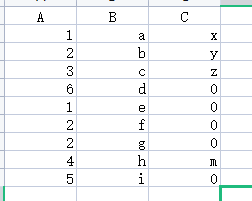
df表里的A列是有重复的,df拼接过来的C列的值,在重复的A值里面只出现一次,求解!!!
用merger实在想出了怎么弄,丢大佬帮帮忙,可以VXHB感谢
pandas如何将相同ID的字符串进行合并:
OUTLINE:
- 问题描述
- 自己的解决方案
- 大神的更优化的解法
- 总结
问题描述
"""
id value
1 A
1 B
1 C
2 D
2 E
2 F
变为:
id value
1 [A,B,C]
2 [D,E,F]
pandas怎么把上面的结构变为下面的形式?
"""自己的解决方案
import pandas as pd
import numpy as np
data = pd.DataFrame({'id':[1,1,1,2,2,2],'value':['A','B','C','D','E','F']})
data1 = np.array(data.groupby(['id']))#按照id进行分类
# 转变成array对象之后,可以根据data1[0][1]查看其结构
id_kinds = 2#id的种类,此例比如1、2共两种
all_value = []
for j in range(2):
value = []
for i in data1[j][1]['value']:
value.append(i)
all_value.append(value)
print(all_value)
#再创建新的dataframe
new_data = pd.DataFrame({'id':[1,2],'value':all_value})
print(new_data)输出结果为:
id value
0 1 [A, B, C]
1 2 [D, E, F]大神的更优化的解法
解法一:可以用sum方法,将字符串进行连接
import pandas as pd
import numpy as np
data = pd.DataFrame({'id':[1,1,1,2,2,2],'value':['A','B','C','D','E','F']})
data1 = data.groupby(by='id')['value'].sum()此时的输出结果为:
id
1 ABC
2 DEF
Name: value, dtype: object但是还不是我们想要的,因为我们还需要在中间加入逗号分隔
① 我们可以先将原始数据的value都变成“,A”
data = pd.DataFrame({'id':[1,1,1,2,2,2],'value':['A','B','C','D','E','F']})
data['value'] = data['value'].apply(lambda x:','+ x)② 然后,对其使用sum方法进行字符串相加
data1 = data.groupby(by='id').sum()此时的输出结果为,value值之前多了“,”
id value
1 ,A,B,C
2 ,D,E,F③ 最后,对该列使用apply函数,去除‘,’
data1['value'] = data1['value'].apply(lambda x :[x[1:]])就得到了最终的结果:
id value
1 [A,B,C]
2 [D,E,F]解法二:对分组之后的结果,直接使用apply函数
一行代码就搞定!
data1 = data.groupby(by='id').apply(lambda x:[','.join(x['value'])])那为什么可以这么做呢?
首先需要剖析的是,groupby之后的数据结构是什么样的,它是由元组构成的(分组名,数据块),数据块也就是dataframe结构。使用以下方式可以查看groupby之后的对象:
for ID,group in group_df:
print(ID)
print(group)apply函数中的x作用的即是数据块(dataframe),通过数据块取value那一行得到的是Series对象,于是可以使用join方法进行操作。
总结
- sum方法不仅可以用于数值计算,还可用于对于一个Series对象而言的字符串相加
a = ['a','b']
c = pd.Series(a).sum()- apply函数非常灵活,不仅可以作用于一个Series对象,还可以作用于一个groupby之后的数据块
data['value'].apply(lambda x :*****)
data.groupby(by='**').apply(lambda x :*****)- lambda匿名函数可以极大优化精简我们的代码,是一个非常灵活好用的函数,记住它!
您好,我是有问必答小助手,您的问题已经有小伙伴解答了,您看下是否解决,可以追评进行沟通哦~
如果有您比较满意的答案 / 帮您提供解决思路的答案,可以点击【采纳】按钮,给回答的小伙伴一些鼓励哦~~
ps:问答VIP仅需29元,即可享受5次/月 有问必答服务,了解详情>>>https://vip.csdn.net/askvip?utm_source=1146287632