requests抓取html, 为什么div中的内容没有被抓取
老哥们,新人入坑,在用requests抓取页面中的图片,主要是想批量下载练练手,下面这张是页面源码:
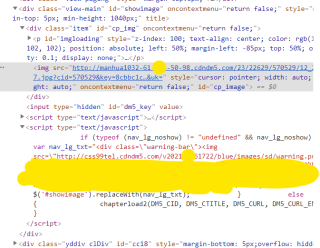
但是我爬取完之后显示id为“cp_img”的div标签内的内容为:
![]()
以下是我的测试代码,主要是想抓到那个id为cp_img的div里面的内容:
import requests as rq
from bs4 import BeautifulSoup as bf
if __name__ == "__main__":
url = 'http://www.1kkk.com/ch66-570484-p2/'
myheaders = {
'User-Agent':'Mozilla/5.0',
'Referer':'http://www.1kkk.com/ch66-570484-p2/'
}
res = rq.get(url=url,headers=myheaders)
res.encoding = 'utf-8'
con = res.text
bf1 = bf(con,'lxml')
with open('file.html','w') as fp:
fp.write(bf1.prettify())
fp.close
imgs = bf1.find_all('div',id='cp_img')
print(imgs)
也查了很多,有说div折叠的,有说动态加载的,但是当时我用chrome抓到的包里也没有目的图片啊
求解
imgs = bf1.find_all('div',id='cp_img').get_text(),还要调用get_text()这个方法获取,find_all只是找到这个标签对象。
如果觉得有帮忙,望采纳
这个div中的内容是通过js读取外部json数据来动态更新的。
requests只能获取网页的静态源代码,动态更新的取不到,
对于动态更新的要用selenium 的 webdriver 爬取。
或者是找真正json数据的地址进行爬取。
您好,我是有问必答小助手,您的问题已经有小伙伴解答了,您看下是否解决,可以追评进行沟通哦~
如果有您比较满意的答案 / 帮您提供解决思路的答案,可以点击【采纳】按钮,给回答的小伙伴一些鼓励哦~~
ps:问答VIP仅需29元,即可享受5次/月 有问必答服务,了解详情>>>https://vip.csdn.net/askvip?utm_source=1146287632
非常感谢您使用有问必答服务,为了后续更快速的帮您解决问题,现诚邀您参与有问必答体验反馈。您的建议将会运用到我们的产品优化中,希望能得到您的支持与协助!
速戳参与调研>>>https://t.csdnimg.cn/Kf0y