python爬取的源代码和检查的网页源代码不一致
python爬取的代码,img标签中的src属性值是这样的,无法打开
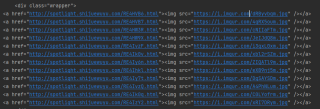
ctrl+u查看的网页源代码,img标签src属性是正常的,可以打开,而且除了src属性,还有其他属性

f12检查里查看的源代码和ctrl+u查看到的源代码一致,不知道问题原因,求解
打不开i.imgur.com网站的图片是因为该网站就登录不上,获取不到图片,可能需要proxy或其他方法才行。
是不是网页存在异步加载呢, 可以试试selenium库
from selenium import webdriver
driver = webdriver.Chrome()
driver.get('网址')
driver.implicitly_wait(10)
您好,我是有问必答小助手,你的问题已经有小伙伴为您解答了问题,您看下是否解决了您的问题,可以追评进行沟通哦~
如果有您比较满意的答案 / 帮您提供解决思路的答案,可以点击【采纳】按钮,给回答的小伙伴一些鼓励哦~~
ps:问答VIP仅需29元,即可享受5次/月 有问必答服务,了解详情>>>https://vip.csdn.net/askvip?utm_source=1146287632
请求页面时加上 headers 头信息试试
headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36',
'Content-Type': 'text/html; charset=utf-8',
}
res = requests.get(url,headers=headers)