python散点图sactter函数x,y轴不按顺序
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from collections import Counter
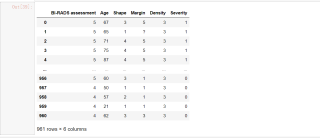
df =pd.read_csv('http://archive.ics.uci.edu/ml/machine-learning-databases/mammographic-masses/mammographic_masses.data', sep=',',header=None)
df.columns = ['BI-RADS assessment','Age','Shape','Margin','Density','Severity']
b= df.sort_values(by='Severity',ascending=False)
b.index = range(len(b))
plt.scatter(b[:50]['Shape'],b[:50]['Age'], label='1')
plt.scatter(b[800:900]['Shape'],b[800:900]['Age'], label='0')
plt.xlabel('Shape')
plt.ylabel('Age')
plt.legend()我是python初学者,
上面的代码是通过鸢尾花代码改过来的,想用UCI上的其他的库,但是输出的散点图x,y轴一直是乱序的
非常感谢大佬能够提供一些帮助,谢谢!!!
如下图:
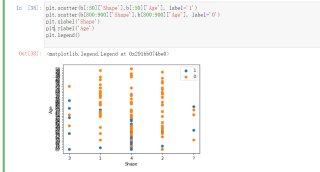
正常情况下, x轴会按照数值排序显示, 这里排序是乱的是因为Shape这一列, 不是数值型, 而是文本型.
而是文本型是因为这列有值为"?"号的数据, 这样这一列实际上是一个分类变量了, 图上的顺序也就乱了.
修改了一下, 把数据进行过滤,并转成整数.(其他列不是数值类型也是上面的原因)
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from collections import Counter
df =pd.read_csv('http://archive.ics.uci.edu/ml/machine-learning-databases/mammographic-masses/mammographic_masses.data', sep=',',header=None)
df.columns = ['BI-RADS assessment','Age','Shape','Margin','Density','Severity']
b= df.sort_values(by='Severity',ascending=False)
b=b[b['Shape']!='?'] # 过滤
b['Shape']=b['Shape'].astype('int') #转整数
b.index = range(len(b))
plt.figure(figsize=(12,12)) # 增加了一句让y轴不重叠
plt.scatter(b[:50]['Shape'],b[:50]['Age'], label='1')
plt.scatter(b[800:900]['Shape'],b[800:900]['Age'], label='0')
plt.xlabel('Shape')
plt.xticks([1,2,3,4])
plt.ylabel('Age')
plt.legend(loc='upper right')
#可通过 查看各列的属性
b.info()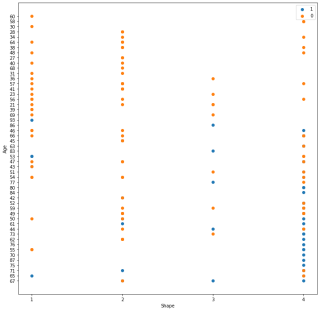
显示没有问题的,可以print(b[:50]['Shape']),看到最先开始出现的值为3,然后是1,4,2,?,这个顺序是和x轴上出现的顺序是一样的。如果看起来别扭,也可以根据shape的值重新排列后再画图。