python如何判断一句英文中的单词是什么词性
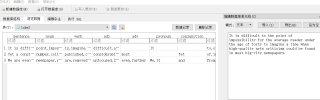
数据表里有英文原句,也有句子中每个单词的词性。要在python根据数据表判断每个单词是什么词性
import sqlite3
#连接数据库
#获取原句
conn = sqlite3.connect('label.db')
cur = conn.cursor()
sql = "select sentence from label"
cur.execute(sql)
sentences = cur.fetchall()
#获取第一句的名词
sql_2 = "select noun from label"
cur.execute(sql_2)
nouns = cur.fetchall()
noun1 = nouns[0]
#获取第一句的动词
sql_3 = "select verb from label"
cur.execute(sql_3)
verbs = cur.fetchall()
verb1 = verbs[0]
for n in noun1:
list_n = n.split(',')
for v in verb1:
list_v = v.split(',')
#拿到第一句的每个单词
for words in sentences[0]:
word1 = words.replace('.', '')
word2 = word1.split()
www = []
for w in word2:
if w in list_n:
w_n = " "+'<font color="red">' + w + " "+ '</font>'
www.append(w_n)
elif w in list_v:
w_v = " "+'<font color="green">' + w + " " + '</font>'
www.append(w_v)
else:
w1 = " "+ w +" "
# print('<span>' + w + '</span>')
www.append(w1)
se2 = "".join(www)
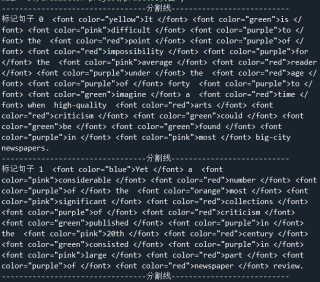
print(se2)只能做到第一句,没办法做到多个句子一起判断
import sqlite3
conn = sqlite3.connect('test2.db')
cur = conn.cursor()
#句子
sql = "select sentence from label"
cur.execute(sql)
sentences = cur.fetchall()
#名词
sql_2 = "select noun from label"
cur.execute(sql_2)
nouns = cur.fetchall()
#动词
sql_3 = "select verb from label"
cur.execute(sql_3)
verbs = cur.fetchall()
#形容词
sql_4 = "select adj from label"
cur.execute(sql_4)
adjs = cur.fetchall()
#副词
sql_5 = "select adv from label"
cur.execute(sql_5)
advs = cur.fetchall()
#连词
sql_6 = "select conjunction from label"
cur.execute(sql_6)
conjunctions = cur.fetchall()
#介词
sql_7 = "select prep from label"
cur.execute(sql_7)
preps = cur.fetchall()
#代词
sql_8 = "select pronoun from label"
cur.execute(sql_8)
pronouns = cur.fetchall()
index=0
for index in range(3):
# print(sentences[index])
# print(nouns[index])
www = []
for sentence in sentences[index]:
words_list=sentence.split()
# print('单词列表',index, words_list)
for noun,verb,adj,adv,conjunction,prep,pronoun in zip(nouns[index],verbs[index],adjs[index],advs[index],conjunctions[index],preps[index],pronouns[index]):
noun_list=noun.split(',')
verb_list=verb.split(',')
adj_list=adj.split(',')
adv_list=adv.split(',')
conjunction_list=conjunction.split(',')
prep_list=prep.split(',')
pronoun_list=pronoun.split(',')
for words in words_list:
if words in noun_list:
words_n = " "+'<font color="red">' + words + " "+ '</font>'
www.append(words_n)
elif words in verb_list:
words_v = " "+'<font color="green">' + words + " " + '</font>'
www.append(words_v)
elif words in adj_list:
words_adj = " "+'<font color="pink">' + words + " " + '</font>'
www.append(words_adj)
elif words in adv_list:
words_adv = " "+'<font color="orange">' + words + " " + '</font>'
www.append(words_adv)
elif words in conjunction_list:
words_conjunction = " "+'<font color="blue">' + words + " " + '</font>'
www.append(words_conjunction)
elif words in prep_list:
words_prep = " "+'<font color="purple">' + words + " " + '</font>'
www.append(words_prep)
elif words in pronoun_list:
words_pronoun = " "+'<font color="yellow">' + words + " " + '</font>'
www.append(words_pronoun)
else:
words_ori = " "+ words +" "
www.append(words_ori)
remaked_sentence = "".join(www)
print("---------------------------------分割线---------------------------")
print('标记句子',index, remaked_sentence)写的很繁琐,但是还是做出来了