python使用python-docx模块读取word表格发生重复
import os
import docx
if __name__=='__main__':
workpath=str(os.getcwdb(),encoding='utf-8') #获取当前目录
filepath=workpath+r'\test2.docx' #获取文件目录
doc1=docx.Document(filepath) #打开文件
tables=doc1.tables
table=tables[0]
for row in table.rows:
for cell in row.cells:
print(cell.text,end=' ')
print('\n')
print('end')
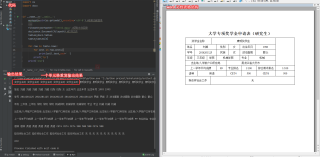
word文件放在云盘里,代码如上,具体问题如下,很多cell读取的时候都重复读取了好多遍,我也不知道怎么回事,这个表格是学校下发的表格,不是自己做的,非常感谢。https://kdocs.cn/l/siUDPGHApKNE
[金山文档] test2.docx
遍历的时候有意识去重就可以了
value_list = list()
for row in table.rows:
temp = list()
for cell in row.cells:
if cell.text not in temp:
temp.append(cell.text)
print(cell.text,end=' ')
print('\n') print('end')
value_list.append(temp)
我也碰到这个问题
把这个Word复制粘贴进excel就会发现这一个单元格实际上是很多单元格,我都采集出来去重了
怎么办啊大哥