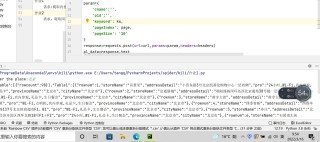
python爬虫请求后 response.text的内容是 -1000,
import requests
import json
if __name__ == "__main__":
url='http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx'
#UA伪装
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.141 Safari/537.36'
}
city = input('enter a city:')
page = input('enter the number of page:')
#参数
data = {
'cname': '',
'pid': '',
'keyword': city,
'pageIndex': page,
'pageSize': '10',
}
#发送请求并接受
response =requests.post(url=url,data=data,headers = headers)
print(type( response))
page_text = json.dumps(response.text)
with open('./KFC.json','w',encoding='utf-8') as fp:
json.dump(page_text,fp=fp,ensure_ascii=False)
print(type(page_text))
print(page_text)
url错了,应为:“http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=cname”
对于POST请求,有些链接问号后面部分不能省略,有些后台会检查该参数
这位同学也是做作业的么?
我也是刚写出来了。
import requests
import json
url = 'http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=keyword'
kw = input('输入:')
data = {
'cname':'',
'pid':'',
'keyword': kw,
'pageIndex': '1',
'pageSize': '100',
}
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 11_1_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36'
}
response = requests.post(url =url,data= data,headers= headers)
page_texe = response.text
# print(page_texe)
fileName = kw +'.html' #定义名字
with open(fileName,'w',encoding='utf-8')as fp:
fp.write(page_texe)
print(fileName,'保存成功')

# 未解决可参考一下
# 测试可以获取
import requests
from fake_useragent import UserAgent
url = 'http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=cname'
headers = {'User-Agent': UserAgent().random}
data = {"cname": "安庆",
"pid": "",
"pageIndex": "1",
"pageSize": "10"
}
html = requests.post(url=url, headers=headers, data=data).text
print(html)

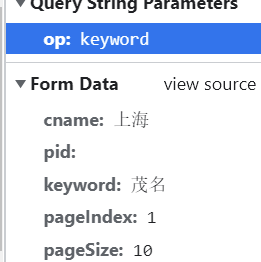
url里面op =cname就可以正常爬,可是如果用op=keyword就不可以,为什么呀
请求参数有问题吧
补充:
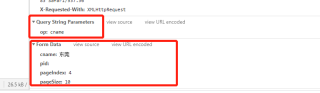
op=cname,该参数不是FormData,所以应该放在链接后面,而不是requests中POST的请求data参数里
wuhu


data = {
'cname': '',
'pid': '',
'keyword': '北京',
'pageIndex':'1',
'pageSize': '10',
}
这样结果和网页的结果一样,如果地址后缀是op=cname,结果和网页上显示的不一样
最后显示的还是-1000
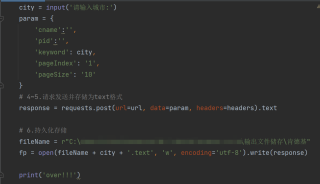
param携带的参数要完整