Python 用jieba分词,没任何作用。求答!!
原本打算用爬到的评论数据,做个词云,在用jieba分词时,发现jieba分词完全没起到作用。
然后自己再写了个简单代码来做测试,但是发现还是没起到作用,代码如下图: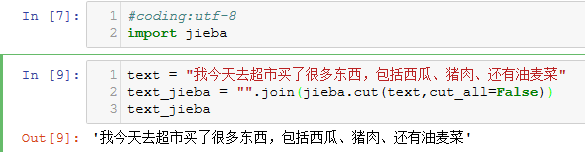
本人是Python新手,没金币,希望各位大佬能解答下,万分感谢!!!
你自己用join又把所有的分词连接起来了,cut返回的生成器中就有所有的词
In [4]: res = jieba.cut(text, cut_all=False)
In [5]: res
Out[5]: <generator object Tokenizer.cut at 0x0000003FB9F9E888>
In [6]: for x in res:
...: print(x)
...:
Building prefix dict from the default dictionary ...
Dumping model to file cache C:\Users\jerry_ou\AppData\Local\Temp\jieba.cache
Loading model cost 0.867 seconds.
Prefix dict has been built succesfully.
今天
我
去
超市
买
了
很多
东西
,
包括
西瓜
,
猪肉
还有
油麦
菜