关于BeutifulSoup对象的find_all()中使用正则表达式的问题
如图所示的网页HTML标签,现想用正则表达式将div class='dg000'或者div class='dgfff'的标签提取出来,而不包括class='dgfff banner-box'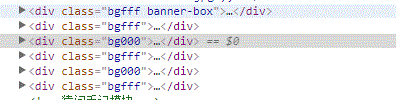
用如下语句提取实现不了,原因是什么呢?
datas=soup.find_all('div',{'class':'re.compile(''bg[f,0]{3}$)})
你先弄清楚你爬取的是动态网页还是静态网页
soup.findAll("div", attrs={"class":re.compile(r'bg[f0]{3}$')})试试
先用if 判断has_key的结果,然后“class"要用“_class"才可以_
到底是bg还是dg
另外,你要匹配000或者fff,而不是0f0或者00f,应该用bg000|bgfff
js动态的数据吧,或者是ajax异步请求的
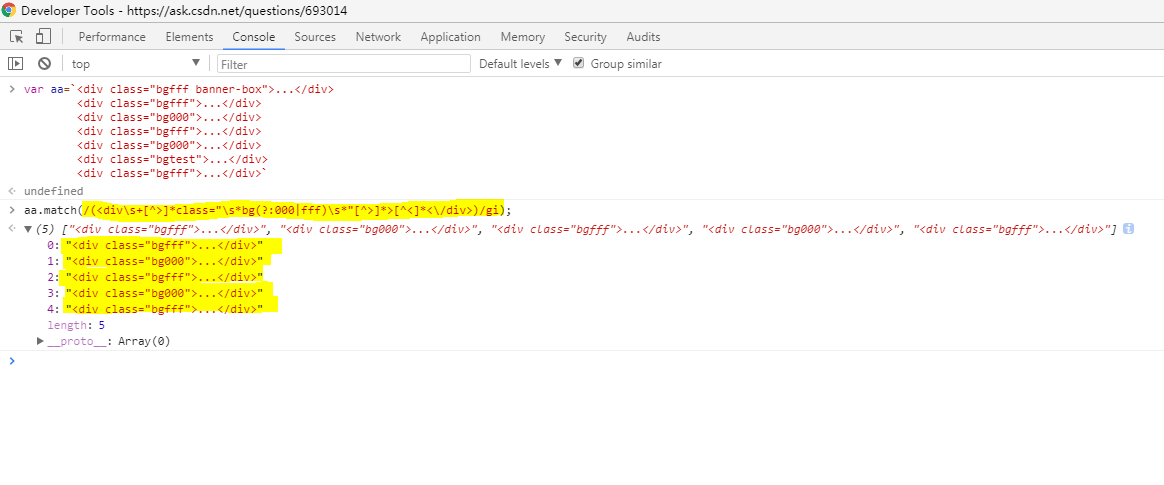
/(
]*class="\s*bg(?:000|fff)\s*"[^>]*>[^<]*<\/div>)/gi
你应该爬虫用的并不是很熟练吧?你可以看下我博客,里面虽然并不能解决你的问题,但应该可以让你知道哪些网页你暂时不好爬。 要爬动态网页需要付出一些学习时间,去了解全新知识。