fwscanf_s函数如何使用
fontpreviewheight = GetDlgItemInt(dlghwndset, 51, NULL, 1);
fontmainheight = GetDlgItemInt(dlghwndset, 52, NULL, 1);
usersetheight = GetDlgItemInt(dlghwndset, 55, NULL, 1);
previewmulti= GetDlgItemInt(dlghwndset, 53, NULL, 1);
mainmulti = GetDlgItemInt(dlghwndset, 54, NULL, 1);
previewwindowswidth= GetDlgItemInt(dlghwndset, 56, NULL, 1);
previewwindowheight= GetDlgItemInt(dlghwndset, 59, NULL, 1);
FILE *file = fopen("set.txt", "w+");
if (file == NULL)
{
MessageBox(NULL, _T("write file error"), _T("write file error"), MB_OK);
}
else
{
if (fwprintf_s(file, _T("%d,%d,%d,%d,%d,%d,%d\n"),fontpreviewheight, fontmainheight,previewmulti,mainmulti,usersetheight, previewwindowswidth, previewwindowheight)< 0)
{
MessageBox(NULL, _T("write file error"), _T("write file error"), MB_OK);
}
}
wchar_t str0[20], str1[20], str2[20], str3[20], str4[20], str5[20], str6[20];
wchar_t a;
fwscanf_s(fileset, _T("%[^,]%c%[^,]%c%[^,]%c%[^,]%c[^,]%c%[^,]%c%[^\n]\n"),
str0,&a, str1, &a, str2, &a, str3, &a, str4, &a, str5, &a, str6);这样写不对。。。
请问这个函数怎么用
我写程序18年,不建议你用 fwscanf_s()这个函数,这样回答估计你不太喜欢,
字符串格式多样,处理也很复杂,通常都需要一套公用的“字符串处理库”来解决各个平台间的字符串转换。
比如Linux平台和Windows平台是有差异的。
我的建议是,首先,fwscanf_s()读文件的方式很慢,在真正项目里使用没有效率,你会被领导责骂。
我们通常都是用fread直接把文件读到缓存里,再在缓存(内存)里批量处理,这样很快。
比如宽字符读出来后,根据平台不同,可以批量转换为多字节,你处理多字节就舒服多了,而且高效稳定。
我贴几个字符串转换函数出来,它能帮你把字符串转换成你想要的格式,供你参考:
(如果能用上,麻烦给点分。我急需分数下载,感激不尽。)
#include "windows.h"
// 宽字符转多字节(ANSI):
void WideToAnsi(const wchar_t* pWideStr, char* pAnsiStr, unsigned int dwBuffLen)
{
if (pAnsiStr == NULL || dwBuffLen == 0)
{
return;
}
if (pWideStr == NULL)
{
return;
}
size_t dwLen = WideCharToMultiByte(CP_ACP, 0, pWideStr, -1, NULL, 0, NULL, NULL);
if (dwLen >= dwBuffLen)
{
dwLen = dwBuffLen - 1;
}
int nRet = WideCharToMultiByte(CP_ACP, 0, pWideStr, -1, pAnsiStr, dwBuffLen, NULL, NULL);
if (nRet == 0)
{
if (GetLastError() == ERROR_INSUFFICIENT_BUFFER)
{
pAnsiStr[dwLen - 1] = 0;
}
else
{
pAnsiStr[0] = 0;
}
}
}
// 宽字符转多字节(UTF8)
void WideToUtf8(const wchar_t* pWideStr, char* pAnsiStr, unsigned int dwBuffLen)
{
if (pAnsiStr == NULL || dwBuffLen == 0)
{
return;
}
if (pWideStr == NULL)
{
return;
}
size_t dwLen = WideCharToMultiByte(CP_UTF8, 0, pWideStr, -1, NULL, 0, NULL, NULL);
if (dwLen >= dwBuffLen)
{
dwLen = dwBuffLen - 1;
}
int nRet = WideCharToMultiByte(CP_UTF8, 0, pWideStr, -1, pAnsiStr, dwBuffLen, NULL, NULL);
if (nRet == 0)
{
if (GetLastError() == ERROR_INSUFFICIENT_BUFFER)
{
pAnsiStr[dwLen - 1] = 0;
}
else
{
pAnsiStr[0] = 0;
}
}
}
// 多字节(ANSI)转宽字符:
void AnsiToWide(const char* pAnsiStr, wchar_t* pWideStr, unsigned int dwBuffLen)
{
if (pAnsiStr == NULL || dwBuffLen == 0)
{
return;
}
if (pWideStr == NULL)
{
return;
}
size_t dwLen = MultiByteToWideChar(CP_ACP, 0, pAnsiStr, -1, NULL, 0);
if (dwLen >= dwBuffLen)
{
dwLen = dwBuffLen - 1;
}
int nRet = MultiByteToWideChar(CP_ACP, 0, pAnsiStr, -1, pWideStr, int(dwLen));
if (nRet == 0)
{
if (GetLastError() == ERROR_INSUFFICIENT_BUFFER)
{
pWideStr[dwLen - 1] = 0;
}
else
{
pWideStr[0] = 0;
}
}
pWideStr[dwLen - 1] = L'\0';
}
// 窄字符(ANSI)转宽字符(UTF8):
void Utf8ToWide(const char* pAnsiStr, wchar_t* pWideStr, unsigned int dwBuffLen)
{
if (pAnsiStr == NULL || dwBuffLen == 0)
{
return;
}
if (pWideStr == NULL)
{
return;
}
size_t dwLen = MultiByteToWideChar(CP_UTF8, 0, pAnsiStr, -1, NULL, 0);
if (dwLen >= dwBuffLen)
{
dwLen = dwBuffLen - 1;
}
int nRet = MultiByteToWideChar(CP_UTF8, 0, pAnsiStr, -1, pWideStr, int(dwLen));
if (nRet == 0)
{
if (GetLastError() == ERROR_INSUFFICIENT_BUFFER)
{
pWideStr[dwLen - 1] = 0;
}
else
{
pWideStr[0] = 0;
}
}
pWideStr[dwLen - 1] = L'\0';
}
fwscanf_s(fileset, _T("%[^,]%c%[^,]%c%[^,]%c%[^,]%c[^,]%c%[^,]%c%[^\n]\n"),
str0, str1, str2, str3, str4, str5,, str6);
这样才对
不需要&a
https://msdn.microsoft.com/zh-cn/library/6ybhk9kc.aspx
当你熟悉标准模板库里的 std::string 之后,你再也不会用这些低级函数了。因为它太受平台限制。
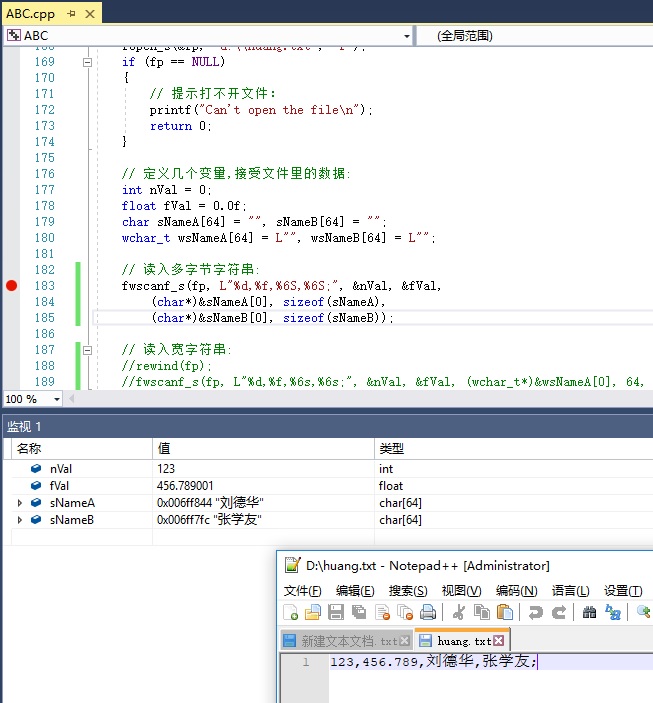
刚说了半天,忘了说那个函数怎么用了,是像下面这样的,比如你的文件里有这样一个字符串:
"123,456.789,刘德华,张学友;"
(假设文件中无双引号)
读的时候是这样的:
/*
假设文件里的内容是:
123,456.789,刘德华,张学友;
*/
// 定义几个变量,接受文件里的数据:
int nVal = 0;
float fVal = 0.0f;
char sNameA[64] = "", sNameB[64] = "";
wchar_t wsNameA[64] = L"", wsNameB[64] = L"";
// 读入多字节字符串:
fwscanf_s(fp, L"%d,%f,%6S,%6S;", &nVal, &fVal, (char*)&sNameA[0], sizeof(sNameA), (char*)&sNameB[0], sizeof(sNameB));
// 读入宽字符串:
fwscanf_s(fp, L"%d,%f,%6s,%6s;", &nVal, &fVal, (wchar_t*)&wsNameA[0], sizeof(wsNameA), (wchar_t*)&wsNameB[0], sizeof(wsNameB));
它在每个字符串后面,都要加一个字符串的长度上限,防止越界。比如上行的 sizeof(sNameA) 和 sizeof(sNameB)。
别忘记给点分数,谢了。