代码运行不了 下载不了图片
#! python3
downloadXkcd.py - Downloads every single XKCD comic.
import requests, os, bs4
url = 'http://xkcd.com' # starting url
os.makedirs('xkcd', exist_ok=True) # store comics in ./xkcd
while not url.endswith('#'):
# Download the page.
print('Downloading page %s...' % url)
res = requests.get(url)
res.raise_for_status()
soup = bs4.BeautifulSoup(res.text, 'lxml')
# Find the URL of the comic image.
comicElem = soup.select('#comic img')
if comicElem == []:
print('Could not find comic image.')
else:
comicUrl = comicElem[0].get('src')
# Download the image.
print('Downloading image %s...' % (comicUrl))
res = requests.get(comicUrl)
res.raise_for_status()
# Save the image to ./xkcd
imageFile = open(os.path.join('xkcd', os.path.basename(comicUrl)), 'wb')
for chunk in res.iter_content(100000):
imageFile.write(chunk)
imageFile.close()
# Get the Prev button's url.
prevLink = soup.select('a[rel="prev"]')[0]
url = 'http://xkcd.com' + prevLink.get('href')
print('Done.')
代码是这样的,但是运行之后就是有错误,想问一下到底是哪里出错了
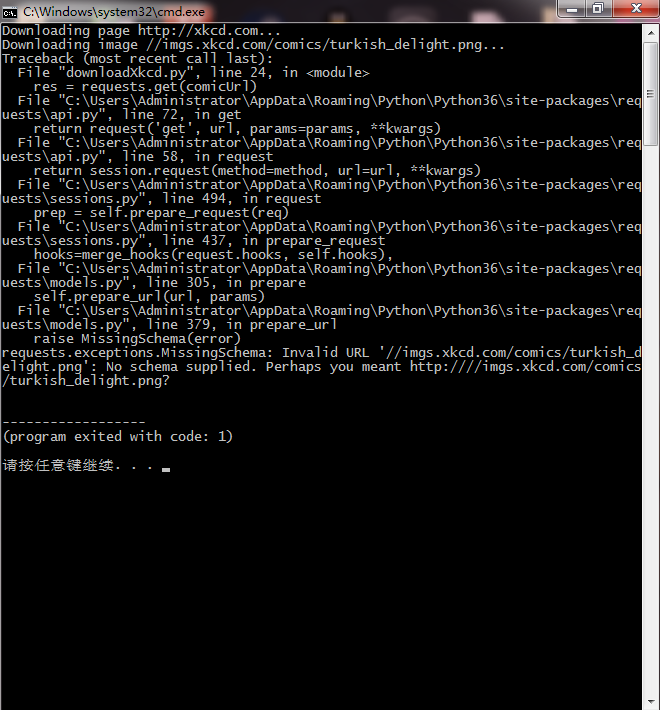
我觉得是不是URL不太对,报错Invalid url
显示为url错误,看了下代码。
试着改一下标红的地方,看看。
# -*- coding: utf-8 -*-
from __future__ import unicode_literals
import requests
import os
import bs4
url = 'http://xkcd.com' # starting url
os.makedirs('xkcd', exist_ok=True) # store comics in ./xkcd
while not url.endswith('#'):
# Download the page.
print('Downloading page %s...' % url)
res = requests.get(url)
res.raise_for_status()
soup = bs4.BeautifulSoup(res.text, 'lxml')
# Find the URL of the comic image.
comicElem = soup.select('#comic img')
if comicElem == []:
print('Could not find comic image.')
else:
** comicUrl = 'http:' + comicElem[0].get('src')
** # Download the image.
print('Downloading image %s...' % (comicUrl))
res = requests.get(comicUrl)
res.raise_for_status()
# Save the image to ./xkcd
imageFile = open(os.path.join('xkcd', os.path.basename(comicUrl)), 'wb')
for chunk in res.iter_content(100000):
imageFile.write(chunk)
imageFile.close()
# Get the Prev button's url.
prevLink = soup.select('a[rel="prev"]')[0]
url = 'http://xkcd.com' + prevLink.get('href')
print('Done.')
res = requests.get(comicUrl)‘
这里出错了
comicUrl 你打印出来看看
这个图片的地址应该是不完整的 需要进行处理为正常的格式