Pixiv.net上通过XPath Helper可以准确获取到想要的,在Python里却无法获取到
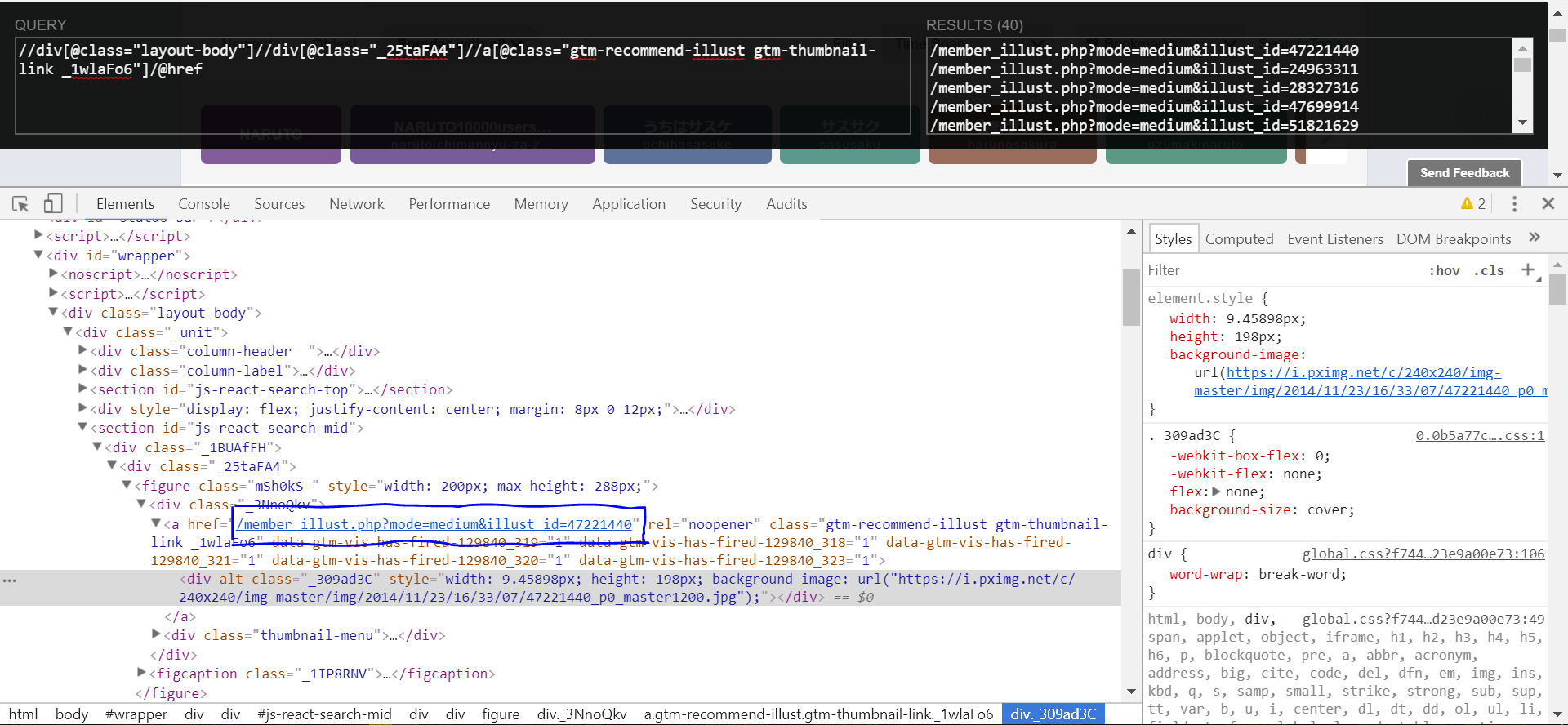
我发现F12查看到的和右键查看到的源代码不一样,Python里返回的是右键查看到的。我该怎么做才能提取到我想要的“/member_illust.php?mode=medium&illust_id=47221440”?
# 获取返回页面数值
page_html = requests.get(html, headers=headers)
# 将html的div 转化为 xml
xmlcontent = etree.HTML(page_html.text)
# 解析HTML文档为HTML DOM模型
# 返回所有匹配成功的列表集合
link_list = xmlcontent.xpath('//div[@class="layout-body"]//div[@class="_25taFA4"]//a[@class="gtm-recommend-illust gtm-thumbnail-link _1wlaFo6"]/@href')
# 直接提取第一个href
for link in link_list:
print(link)
https://blog.csdn.net/love666666shen/article/details/72613143
requests 只能拿到原始的 response html, 如果你这个页面是 动态加载的,requests 是拿不到完整的 html的,
你可以print(page_html.text) 看看 你要的元素 requests拿到了没有
如果没有拿到的话 可以考虑 用 selenium 模拟浏览器来拿
自回答:
现在明白了,感谢@qq-38692254
request.get 获取返回页面是和右键查看源代码一致的,而不是F12
有的页面是动态加载的,所以右键查看源代码和F12返回的不一样
这种情况下运用正则表达式匹配
pattern = re.compile(r'illustId":"\d+"')
img_quote = re.findall(pattern, html)
for quote in img_quote:
# 直接提取图片href
pattern = re.compile(r'\d+')
href = re.findall(pattern, quote)[0]
fullUrl = ".../member_illust.php?mode=medium&illust_id=" + href