采集网页返回无数据,求解决方案
使用C#采集网页:http://search.10jqka.com.cn/stockpick/search?typed=1&preParams=&ts=1&f=1&qs=result_rewrite&selfsectsn=&querytype=stock&searchfilter=&tid=stockpick&w=%E7%AE%80%E7%A7%B0%E5%8F%98%E5%8A%A8%E6%97%A5%E6%98%AF2010%E5%B9%B4%E4%BB%A5%E6%9D%A5&queryarea=
原来可以返回带数据的html,可从html中采集token值
但现在只能返回:
“<html><body>
<script src="//s.thsi.cn/js/chameleon/chameleon.min.1519305.js" type="text/javascript"></script>
<script language="javascript" type="text/javascript"> window.location.href="http://search.10jqka.com.cn/stockpick/search?typed=1&preParams=&ts=1&f=1&qs=result_rewrite&selfsectsn=&querytype=stock&searchfilter=&tid=stockpick&w=%E7%AE%80%E7%A7%B0%E5%8F%98%E5%8A%A8%E6%97%A5%E6%98%AF2010%E5%B9%B4%E4%BB%A5%E6%9D%A5&queryarea=";
</script>
</body></html>”
请问该问题怎么解决?
以下是我使用的方法,另外使用System.Net.WebClient方法返回为空。
public string GetMoths(string url, string WebCodeStr){
Encoding WebCode = Encoding.GetEncoding(WebCodeStr);
System.GC.Collect(); // 避免操作超时
HttpWebRequest wReq = (HttpWebRequest)WebRequest.Create(@url);
System.Net.ServicePointManager.DefaultConnectionLimit = 200;
wReq.KeepAlive = false;
wReq.UserAgent = @"Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.0; .NET CLR 1.1.4322; .NET CLR 2.0.50215;)";
wReq.Method = "GET"; // HttpWebRequest.Method 属性 获取或设置请求的方法。
wReq.Timeout = 30000; //设置页面超时时间为30秒
HttpWebResponse wResp = null;
try { wResp = (HttpWebResponse)wReq.GetResponse(); }
catch (WebException ex) { var e1=ex; return null; } //
Stream respStream = wResp.GetResponseStream();
//判断网页编码,如果判断编码和读取流不放在一个方法,使用StreamReader会出现无法读取流的错误
StreamReader reader = new StreamReader(respStream, WebCode);
string strWebHtml = reader.ReadToEnd(); // 从流的当前位置到末尾读取流。
respStream.Close();reader.Close();reader.Dispose();
if (wReq != null) { wReq.Abort(); wReq = null; }
if (wResp != null) { wResp.Close(); wResp.Dispose(); wResp = null;}
return strWebHtml;
}
看了下,主要是有个cookie v,这个是判断是否要输出跳转的html代码用的,由
s.thsi.cn/js/chameleon/chameleon.min.1519305.js
这个js文件按生成,这个文件压缩过,看起来费力,是通过TOKEN_SERVER_TIME计算出来的,不想看代码了,这个cookie有效期有30年左右,所以你只需要通过浏览器开发工具获取一次v这个cookie附带上就可以,下面的代码的v值是昨天晚上获取的,今天早上来还能用、
public string GetMoths(string url, string WebCodeStr)
{
Encoding WebCode = Encoding.GetEncoding(WebCodeStr);
System.GC.Collect(); // 避免操作超时
HttpWebRequest wReq = (HttpWebRequest)WebRequest.Create(url);
System.Net.ServicePointManager.DefaultConnectionLimit = 200;
///////////////////////
CookieContainer cc = new CookieContainer();
cc.Add(new Cookie("v", "AhSuO1TEMkngSaaFhPUUQ_Iq5VOgbThXepHMm671oB8imb5B1n0I58qhnCr8", "/", "search.10jqka.com.cn"));
wReq.CookieContainer = cc;
///////////////////////
wReq.KeepAlive = false;
wReq.UserAgent = @"Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.0; .NET CLR 1.1.4322; .NET CLR 2.0.50215;)";
wReq.Method = "GET"; // HttpWebRequest.Method 属性 获取或设置请求的方法。
wReq.Timeout = 30000; //设置页面超时时间为30秒
HttpWebResponse wResp = null;
try { wResp = (HttpWebResponse)wReq.GetResponse(); }
catch (WebException ex) { return ex.Message; } //
Stream respStream = wResp.GetResponseStream();
//判断网页编码,如果判断编码和读取流不放在一个方法,使用StreamReader会出现无法读取流的错误
StreamReader reader = new StreamReader(respStream, WebCode);
string strWebHtml = reader.ReadToEnd(); // 从流的当前位置到末尾读取流。
respStream.Close(); reader.Close(); reader.Dispose();
if (wReq != null) { wReq.Abort(); wReq = null; }
if (wResp != null) { wResp.Close(); wResp = null; }
return strWebHtml;
}
网站内部有验证 GET请求时带上cookie 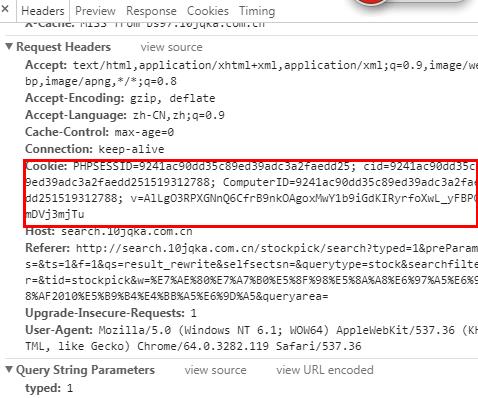
其中cookie中的数据在源码中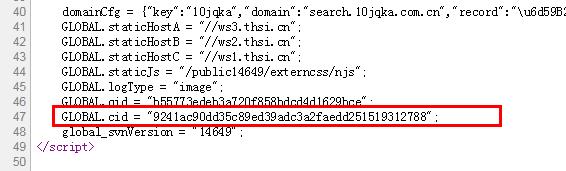
请求成功 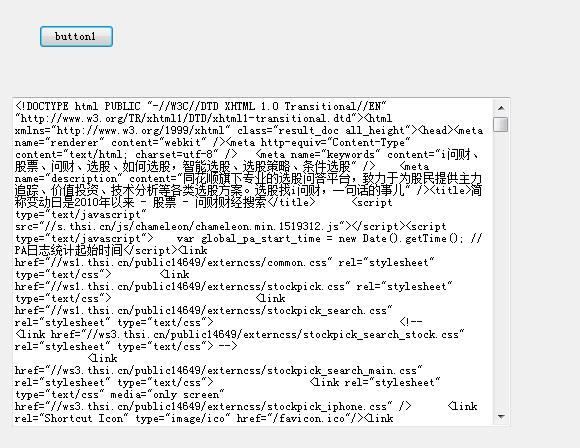
private string GetHttpWebRequest(string url)
{
HttpWebResponse result;
Uri uri = new Uri(url);
HttpWebRequest myReq = (HttpWebRequest)WebRequest.Create(uri);
myReq.UserAgent = "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36";
myReq.Accept = "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8";
myReq.KeepAlive = true;
myReq.Headers.Add("Accept-Language", "zh-cn,en-us;q=0.5");
myReq.Headers.Add("Cookie", "__guid=190516137.2852421027010729000.1519310162432.6685; PHPSESSID=5c5dcbfa0ef2a3335422ddf9b54c6ab6; monitor_count=8; v=AkN-rGGGHSTYR9FQvOjWwO6l0gz7uNf6EUwbLnUgn6IZNGnw_YhnSiEcq3uH; cid=5c5dcbfa0ef2a3335422ddf9b54c6ab61519310215; ComputerID=5c5dcbfa0ef2a3335422ddf9b54c6ab61519310215");
myReq.ContentType = "text/html;charset=utf-8";
myReq.Method = "GET";
try
{
result = (HttpWebResponse)myReq.GetResponse();
}
catch (WebException ex)
{
result = (HttpWebResponse)ex.Response;
}
Stream receviceStream = result.GetResponseStream();
StreamReader readerOfStream = new StreamReader(receviceStream, System.Text.Encoding.GetEncoding("utf-8"));
string strHTML = readerOfStream.ReadToEnd();
readerOfStream.Close();
receviceStream.Close();
result.Close();
return strHTML;
}
myReq.Headers.Add("Cookie", "PHPSESSID=9241ac90dd35c89ed39adc3a2faedd25; cid=9241ac90dd35c89ed39adc3a2faedd251519312788; ComputerID=9241ac90dd35c89ed39adc3a2faedd251519312788; v=AlLgO3RPXGNnQ6CfrB9nkOAgoxMwY1b9iGdKIRyrfoXwL_yFBPOmDVj3mjTu");