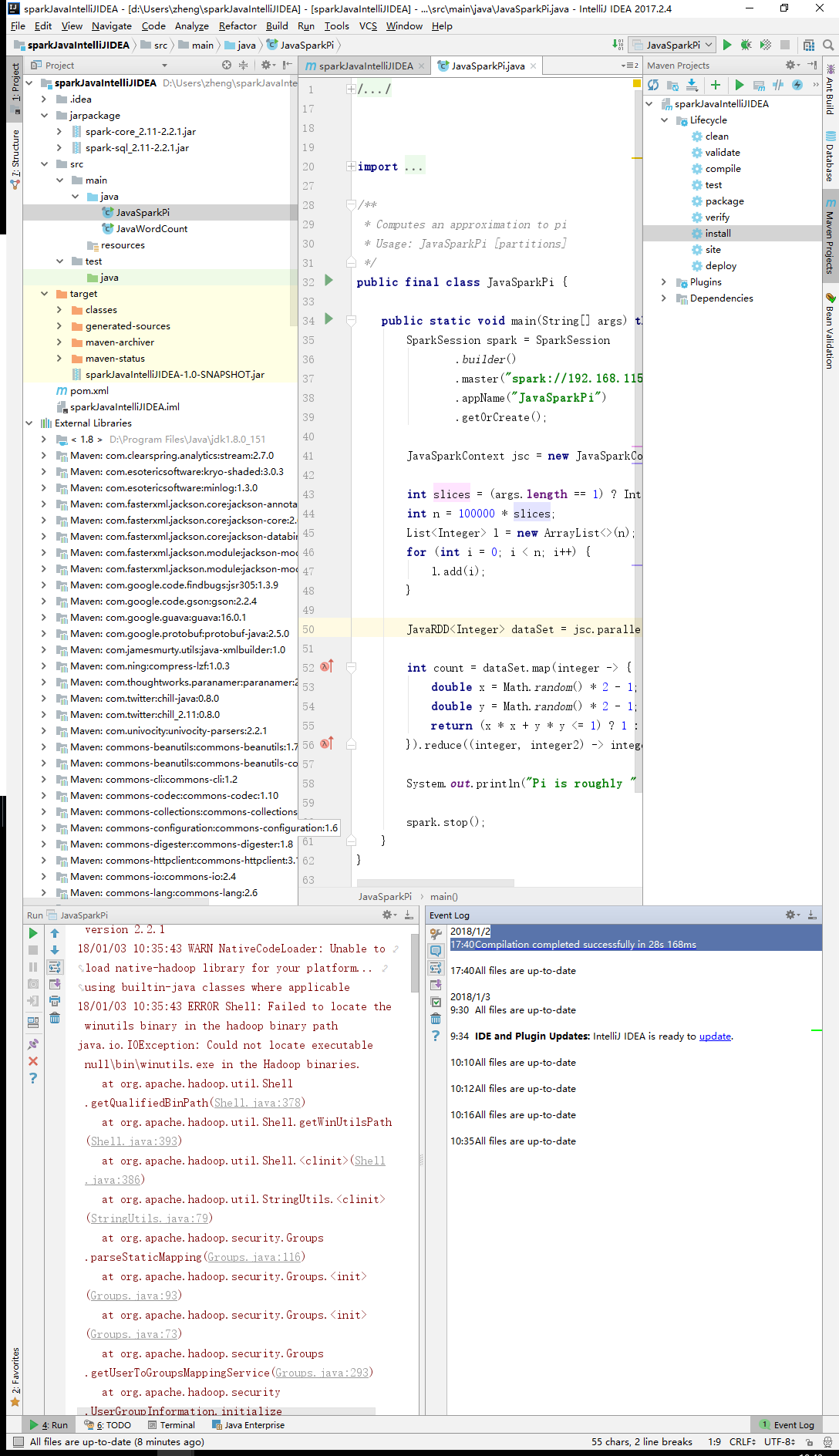
java连接spark 没有运算结果
idea 代码是这样的:
public final class JavaSparkPi {
public static void main(String[] args) throws Exception {
SparkSession spark = SparkSession
.builder()
.master("spark://192.168.115.128:7077")
.appName("JavaSparkPi")
.getOrCreate();
JavaSparkContext jsc = new JavaSparkContext(spark.sparkContext());
int slices = (args.length == 1) ? Integer.parseInt(args[0]) : 2;
int n = 100000 * slices;
List<Integer> l = new ArrayList<>(n);
for (int i = 0; i < n; i++) {
l.add(i);
}
JavaRDD<Integer> dataSet = jsc.parallelize(l, slices);
int count = dataSet.map(integer -> {
double x = Math.random() * 2 - 1;
double y = Math.random() * 2 - 1;
return (x * x + y * y <= 1) ? 1 : 0;
}).reduce((integer, integer2) -> integer + integer2);
System.out.println("Pi is roughly " + 4.0 * count / n);
spark.stop();
}
}
idea控制台是这样的:
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
18/01/03 10:35:41 INFO SparkContext: Running Spark version 2.2.1
18/01/03 10:35:43 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
18/01/03 10:35:43 ERROR Shell: Failed to locate the winutils binary in the hadoop binary path
java.io.IOException: Could not locate executable null\bin\winutils.exe in the Hadoop binaries.
at org.apache.hadoop.util.Shell.getQualifiedBinPath(Shell.java:378)
at org.apache.hadoop.util.Shell.getWinUtilsPath(Shell.java:393)
at org.apache.hadoop.util.Shell.(Shell.java:386)
at org.apache.hadoop.util.StringUtils.(StringUtils.java:79)
at org.apache.hadoop.security.Groups.parseStaticMapping(Groups.java:116)
at org.apache.hadoop.security.Groups.(Groups.java:93)
at org.apache.hadoop.security.Groups.(Groups.java:73)
at org.apache.hadoop.security.Groups.getUserToGroupsMappingService(Groups.java:293)
at org.apache.hadoop.security.UserGroupInformation.initialize(UserGroupInformation.java:283)
at org.apache.hadoop.security.UserGroupInformation.ensureInitialized(UserGroupInformation.java:260)
at org.apache.hadoop.security.UserGroupInformation.loginUserFromSubject(UserGroupInformation.java:789)
at org.apache.hadoop.security.UserGroupInformation.getLoginUser(UserGroupInformation.java:774)
at org.apache.hadoop.security.UserGroupInformation.getCurrentUser(UserGroupInformation.java:647)
at org.apache.spark.util.Utils$$anonfun$getCurrentUserName$1.apply(Utils.scala:2424)
at org.apache.spark.util.Utils$$anonfun$getCurrentUserName$1.apply(Utils.scala:2424)
at scala.Option.getOrElse(Option.scala:121)
at org.apache.spark.util.Utils$.getCurrentUserName(Utils.scala:2424)
at org.apache.spark.SparkContext.(SparkContext.scala:295)
at org.apache.spark.SparkContext$.getOrCreate(SparkContext.scala:2516)
at org.apache.spark.sql.SparkSession$Builder$$anonfun$6.apply(SparkSession.scala:918)
at org.apache.spark.sql.SparkSession$Builder$$anonfun$6.apply(SparkSession.scala:910)
at scala.Option.getOrElse(Option.scala:121)
at org.apache.spark.sql.SparkSession$Builder.getOrCreate(SparkSession.scala:910)
at JavaSparkPi.main(JavaSparkPi.java:39)
18/01/03 10:35:43 INFO SparkContext: Submitted application: JavaSparkPi
18/01/03 10:35:44 INFO SecurityManager: Changing view acls to: wmx
18/01/03 10:35:44 INFO SecurityManager: Changing modify acls to: wmx
18/01/03 10:35:44 INFO SecurityManager: Changing view acls groups to:
18/01/03 10:35:44 INFO SecurityManager: Changing modify acls groups to:
18/01/03 10:35:44 INFO SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(wmx); groups with view permissions: Set(); users with modify permissions: Set(wmx); groups with modify permissions: Set()
18/01/03 10:35:45 INFO Utils: Successfully started service 'sparkDriver' on port 62919.
18/01/03 10:35:45 INFO SparkEnv: Registering MapOutputTracker
18/01/03 10:35:45 INFO SparkEnv: Registering BlockManagerMaster
18/01/03 10:35:45 INFO BlockManagerMasterEndpoint: Using org.apache.spark.storage.DefaultTopologyMapper for getting topology information
18/01/03 10:35:45 INFO BlockManagerMasterEndpoint: BlockManagerMasterEndpoint up
18/01/03 10:35:45 INFO DiskBlockManager: Created local directory at C:\Users\wmx\AppData\Local\Temp\blockmgr-37c3cc47-e21d-498b-b0ec-e987996a39cd
18/01/03 10:35:45 INFO MemoryStore: MemoryStore started with capacity 899.7 MB
18/01/03 10:35:45 INFO SparkEnv: Registering OutputCommitCoordinator
18/01/03 10:35:46 INFO Utils: Successfully started service 'SparkUI' on port 4040.
18/01/03 10:35:46 INFO SparkUI: Bound SparkUI to 0.0.0.0, and started at http://172.21.96.1:4040
18/01/03 10:35:47 INFO StandaloneAppClient$ClientEndpoint: Connecting to master spark://192.168.115.128:7077...
18/01/03 10:35:47 INFO TransportClientFactory: Successfully created connection to /192.168.115.128:7077 after 105 ms (0 ms spent in bootstraps)
18/01/03 10:35:48 INFO StandaloneSchedulerBackend: Connected to Spark cluster with app ID app-20180102183557-0004
18/01/03 10:35:48 INFO StandaloneAppClient$ClientEndpoint: Executor added: app-20180102183557-0004/0 on worker-20180101224135-192.168.115.128-37401 (192.168.115.128:37401) with 1 cores
18/01/03 10:35:48 INFO StandaloneSchedulerBackend: Granted executor ID app-20180102183557-0004/0 on hostPort 192.168.115.128:37401 with 1 cores, 1024.0 MB RAM
18/01/03 10:35:48 INFO StandaloneAppClient$ClientEndpoint: Executor updated: app-20180102183557-0004/0 is now RUNNING
18/01/03 10:35:48 INFO Utils: Successfully started service 'org.apache.spark.network.netty.NettyBlockTransferService' on port 62942.
18/01/03 10:35:48 INFO NettyBlockTransferService: Server created on 172.21.96.1:62942
18/01/03 10:35:48 INFO BlockManager: Using org.apache.spark.storage.RandomBlockReplicationPolicy for block replication policy
18/01/03 10:35:48 INFO BlockManagerMaster: Registering BlockManager BlockManagerId(driver, 172.21.96.1, 62942, None)
18/01/03 10:35:48 INFO BlockManagerMasterEndpoint: Registering block manager 172.21.96.1:62942 with 899.7 MB RAM, BlockManagerId(driver, 172.21.96.1, 62942, None)
18/01/03 10:35:48 INFO BlockManagerMaster: Registered BlockManager BlockManagerId(driver, 172.21.96.1, 62942, None)
18/01/03 10:35:48 INFO BlockManager: Initialized BlockManager: BlockManagerId(driver, 172.21.96.1, 62942, None)
18/01/03 10:35:50 INFO StandaloneSchedulerBackend: SchedulerBackend is ready for scheduling beginning after reached minRegisteredResourcesRatio: 0.0
18/01/03 10:35:51 INFO SparkContext: Starting job: reduce at JavaSparkPi.java:56
18/01/03 10:35:51 INFO DAGScheduler: Got job 0 (reduce at JavaSparkPi.java:56) with 2 output partitions
18/01/03 10:35:51 INFO DAGScheduler: Final stage: ResultStage 0 (reduce at JavaSparkPi.java:56)
18/01/03 10:35:51 INFO DAGScheduler: Parents of final stage: List()
18/01/03 10:35:51 INFO DAGScheduler: Missing parents: List()
18/01/03 10:35:51 INFO DAGScheduler: Submitting ResultStage 0 (MapPartitionsRDD[1] at map at JavaSparkPi.java:52), which has no missing parents
18/01/03 10:35:52 INFO MemoryStore: Block broadcast_0 stored as values in memory (estimated size 3.0 KB, free 899.7 MB)
这很明显是一个想把spark在windows上运行的错误,然而spark要依赖hadoop,而hadoop需要在windows编译,hadoop在windows编译后会产生winutils.exe文件,在windows本地运行spark代码是要配置hadoop环境变量的,建议如下
1.找个windows编译后的hadoop,并配置环境变量
2.下载相应要用的spark并配置环境变量
3.然后就可以在windows上开心的运行代码了,但是 但是master要设置成 .master("local[*])
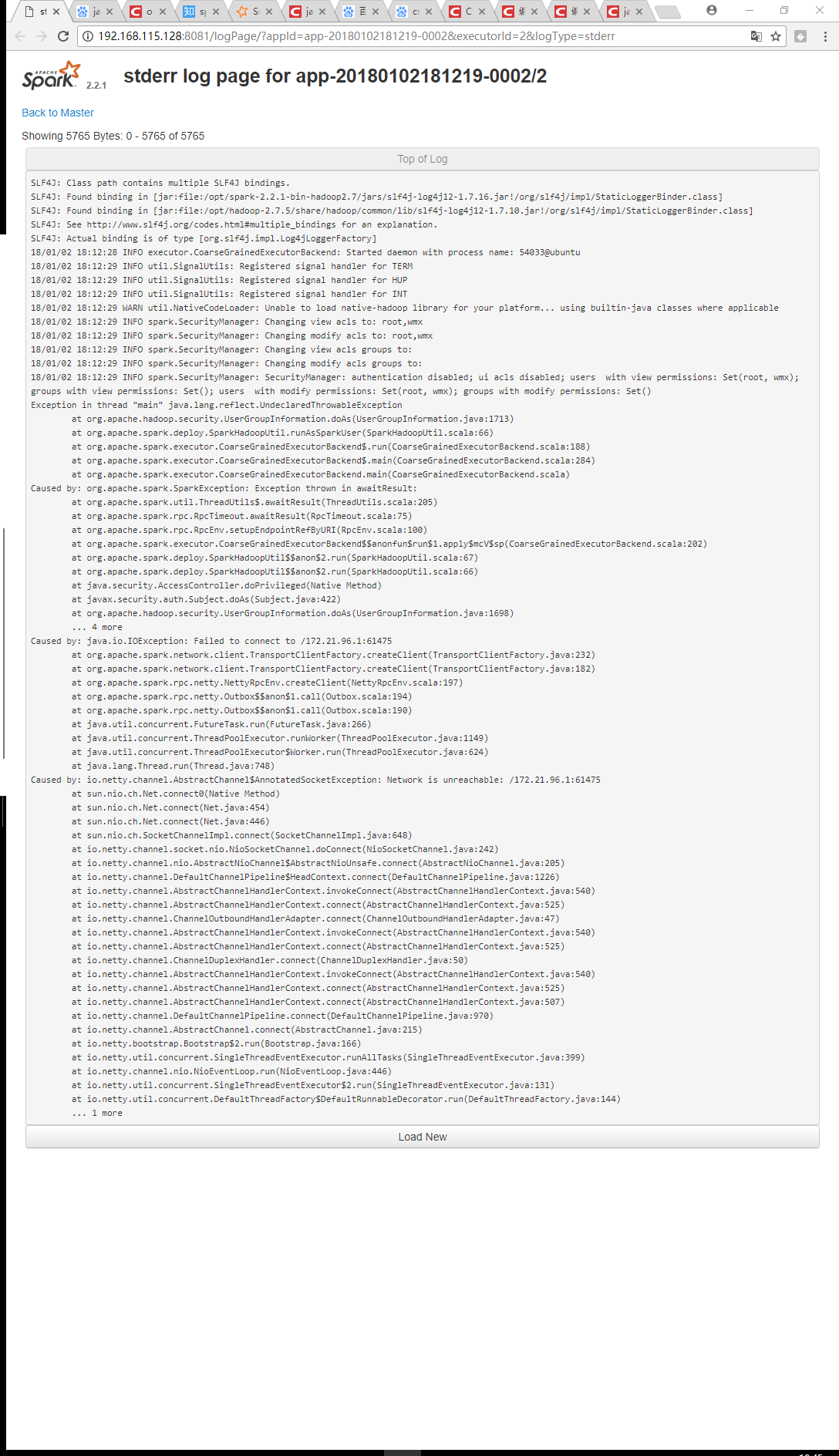
spark集群日志是这样的:
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/opt/spark-2.2.1-bin-hadoop2.7/jars/slf4j-log4j12-1.7.16.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/opt/hadoop-2.7.5/share/hadoop/common/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
18/01/02 18:12:28 INFO executor.CoarseGrainedExecutorBackend: Started daemon with process name: 54033@ubuntu
18/01/02 18:12:29 INFO util.SignalUtils: Registered signal handler for TERM
18/01/02 18:12:29 INFO util.SignalUtils: Registered signal handler for HUP
18/01/02 18:12:29 INFO util.SignalUtils: Registered signal handler for INT
18/01/02 18:12:29 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
18/01/02 18:12:29 INFO spark.SecurityManager: Changing view acls to: root,wmx
18/01/02 18:12:29 INFO spark.SecurityManager: Changing modify acls to: root,wmx
18/01/02 18:12:29 INFO spark.SecurityManager: Changing view acls groups to:
18/01/02 18:12:29 INFO spark.SecurityManager: Changing modify acls groups to:
18/01/02 18:12:29 INFO spark.SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(root, wmx); groups with view permissions: Set(); users with modify permissions: Set(root, wmx); groups with modify permissions: Set()
Exception in thread "main" java.lang.reflect.UndeclaredThrowableException
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1713)
at org.apache.spark.deploy.SparkHadoopUtil.runAsSparkUser(SparkHadoopUtil.scala:66)
at org.apache.spark.executor.CoarseGrainedExecutorBackend$.run(CoarseGrainedExecutorBackend.scala:188)
at org.apache.spark.executor.CoarseGrainedExecutorBackend$.main(CoarseGrainedExecutorBackend.scala:284)
at org.apache.spark.executor.CoarseGrainedExecutorBackend.main(CoarseGrainedExecutorBackend.scala)
Caused by: org.apache.spark.SparkException: Exception thrown in awaitResult:
at org.apache.spark.util.ThreadUtils$.awaitResult(ThreadUtils.scala:205)
at org.apache.spark.rpc.RpcTimeout.awaitResult(RpcTimeout.scala:75)
at org.apache.spark.rpc.RpcEnv.setupEndpointRefByURI(RpcEnv.scala:100)
at org.apache.spark.executor.CoarseGrainedExecutorBackend$$anonfun$run$1.apply$mcV$sp(CoarseGrainedExecutorBackend.scala:202)
at org.apache.spark.deploy.SparkHadoopUtil$$anon$2.run(SparkHadoopUtil.scala:67)
at org.apache.spark.deploy.SparkHadoopUtil$$anon$2.run(SparkHadoopUtil.scala:66)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:422)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1698)
... 4 more
Caused by: java.io.IOException: Failed to connect to /172.21.96.1:61475
at org.apache.spark.network.client.TransportClientFactory.createClient(TransportClientFactory.java:232)
at org.apache.spark.network.client.TransportClientFactory.createClient(TransportClientFactory.java:182)
at org.apache.spark.rpc.netty.NettyRpcEnv.createClient(NettyRpcEnv.scala:197)
at org.apache.spark.rpc.netty.Outbox$$anon$1.call(Outbox.scala:194)
at org.apache.spark.rpc.netty.Outbox$$anon$1.call(Outbox.scala:190)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
Caused by: io.netty.channel.AbstractChannel$AnnotatedSocketException: Network is unreachable: /172.21.96.1:61475
at sun.nio.ch.Net.connect0(Native Method)
at sun.nio.ch.Net.connect(Net.java:454)
at sun.nio.ch.Net.connect(Net.java:446)
at sun.nio.ch.SocketChannelImpl.connect(SocketChannelImpl.java:648)
at io.netty.channel.socket.nio.NioSocketChannel.doConnect(NioSocketChannel.java:242)
at io.netty.channel.nio.AbstractNioChannel$AbstractNioUnsafe.connect(AbstractNioChannel.java:205)
at io.netty.channel.DefaultChannelPipeline$HeadContext.connect(DefaultChannelPipeline.java:1226)
at io.netty.channel.AbstractChannelHandlerContext.invokeConnect(AbstractChannelHandlerContext.java:540)
at io.netty.channel.AbstractChannelHandlerContext.connect(AbstractChannelHandlerContext.java:525)
at io.netty.channel.ChannelOutboundHandlerAdapter.connect(ChannelOutboundHandlerAdapter.java:47)
at io.netty.channel.AbstractChannelHandlerContext.invokeConnect(AbstractChannelHandlerContext.java:540)
at io.netty.channel.AbstractChannelHandlerContext.connect(AbstractChannelHandlerContext.java:525)
at io.netty.channel.ChannelDuplexHandler.connect(ChannelDuplexHandler.java:50)
at io.netty.channel.AbstractChannelHandlerContext.invokeConnect(AbstractChannelHandlerContext.java:540)
at io.netty.channel.AbstractChannelHandlerContext.connect(AbstractChannelHandlerContext.java:525)
at io.netty.channel.AbstractChannelHandlerContext.connect(AbstractChannelHandlerContext.java:507)
at io.netty.channel.DefaultChannelPipeline.connect(DefaultChannelPipeline.java:970)
at io.netty.channel.AbstractChannel.connect(AbstractChannel.java:215)
at io.netty.bootstrap.Bootstrap$2.run(Bootstrap.java:166)
at io.netty.util.concurrent.SingleThreadEventExecutor.runAllTasks(SingleThreadEventExecutor.java:399)
at io.netty.channel.nio.NioEventLoop.run(NioEventLoop.java:446)
at io.netty.util.concurrent.SingleThreadEventExecutor$2.run(SingleThreadEventExecutor.java:131)
at io.netty.util.concurrent.DefaultThreadFactory$DefaultRunnableDecorator.run(DefaultThreadFactory.java:144)
... 1 more
java.io.IOException: Could not locate executable null\bin\winutils.exe in the Hadoop binaries.
这里错误已经很清楚了 没有winutils ,这个应该是在windows上跑的,winutils.exe 是hadoop 访问windows用的,
你的数据不来自Hadoop, 你看看你有没有hadoop的配置文件.先把他删除.
winutils 也可以找一个 放进去.
: Failed to connect to /172.21.96.1:61475 集群错误也很明显啊,,,估计都没搭建好,防火 墙关了吧. 搭建完了用 spark-shell测试一下.