关于单链表中的头结点和尾结点问题
如题,对于单链表的头指针、头结点、和尾结点一直有点概念模糊。
void CreateListR(ListNode* &L, int a[], int n)
{
L = (ListNode *)malloc(sizeof(ListNode));
L->next = nullptr; //建立空表
ListNode *s;
ListNode *r; //指向尾端结点
r = L;
for (int i = 0; i < n; i++)
{
s = (ListNode *)malloc(sizeof(ListNode));
s->data = a[i];
r->next = s;
r = s;
}
r->next = nullptr; //最后将r->next置为nullptr
}
当我用如上尾插法建立一个单链表的时候,
int a[5] = {1,2,3,4,3};
ListNode *L;
CreateListR(L, a, 5);
最后得到的单链表是不是如图所示: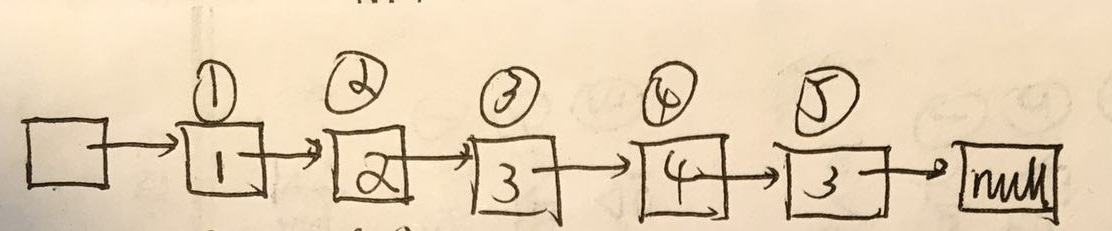
就是有一个头结点,其不为nullptr,但是没有存data,最后r->next = nullptr;这是将最后一个有值的结点的next指针指向了一个nullptr,所以是不是其实最后还有一个尾结点,这个结点为nullptr,但是如果统计结点的时候其实它也是一个结点的存在?
另外,当我创建好了单链表过后,如果我其他函数需要用到该表,例如:
int ListLength(ListNode* L)
{
int length = 0;
ListNode *p = L;
while (p->next != nullptr)
{
length++;
p = p->next;
}
return length;
}
我传入的L是不是之前创建的链表的头结点(就是没有存储data,next指针指向第一个真正存储data的那一个结点)?
没有必要特别区分尾节点和头节点。也就是你所谓不存数据的那个节点的存在纯属多余。
直接第一个节点开始就好了。至于尾节点,如果遍历的过程中遇到节点next == NULL自然就是了,也不需要额外的区分。
数据结构里说的带头节点的链表,会有一个叫head的结构体,指向不带头节点里说的第一个节点。但是就你的代码,就是不带头节点的。
如果回答满意,请点下我回答右边的采纳。如果有不明白的请追问。谢谢