python爬虫爬取腾讯新闻评论
python小白一枚,刚开始学爬虫,遇到一个动态网页爬取问题,请教各位大神。
需要爬取http://view.news.qq.com/original/intouchtoday/n4083.html
这篇新闻的评论内容,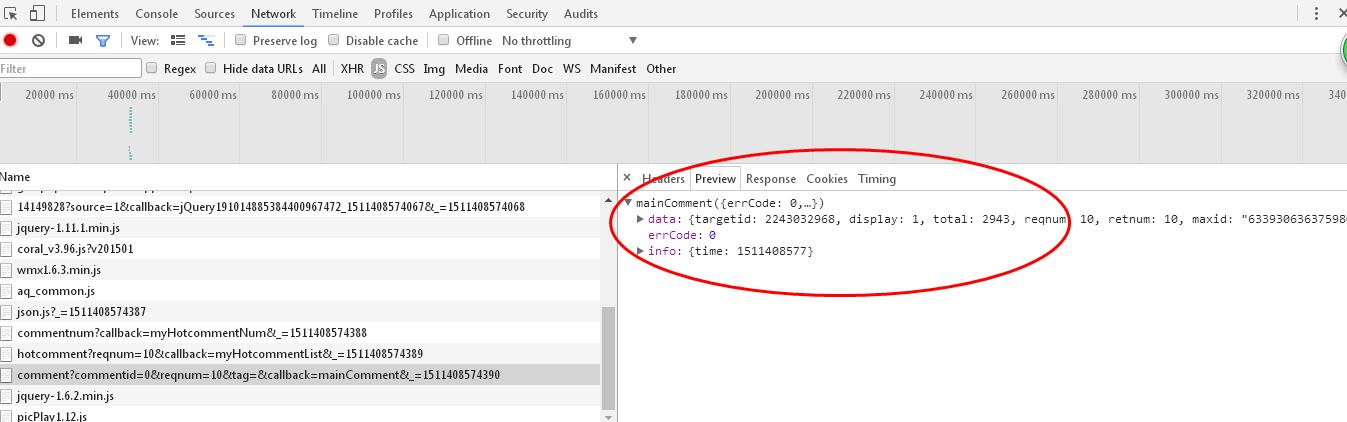
但是在找到了目标request url:
http://coral.qq.com/article/2243032968/comment?commentid=0&reqnum=10&tag=&ca,llback=mainComment&_=1511408574390
,不知道怎么提取里面的评论内容,且里面的内容类似于\u***这样的乱码
需要先把内容的mainComment()去掉,它里面是一个json,然后就可以处理,\u是表示unicode的字符。
In [24]: sess = requests.Session()
In [24]: sess.headers.update({'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Geck
...: o) Chrome/49.0.2623.221 Safari/537.36 SE 2.X MetaSr 1.0'})
In [24]: res = sess.get("http://coral.qq.com/article/2243032968/comment?commentid=0&reqnum=10&tag=&callback=mainCommen
...: t&_=1511408574390")
g = re.match("mainComment\\((.+)\\)", res.text)
In [24]: out = json.loads(g.group(1))
In [23]: print(out["data"]["commentid"][0]["content"])
方便面可以吃不放调料,自己煮,自己搭配
把这个接口拿到的数据转换成json对象就行了
类似于
\u***
这样的数据是Unicode编码的字符串
转码一下就好了
你可以先找一个简单一点的现成的小demo