ssd跑ssd_pascal_webcam.py时候摄像头只有画面没有识别框
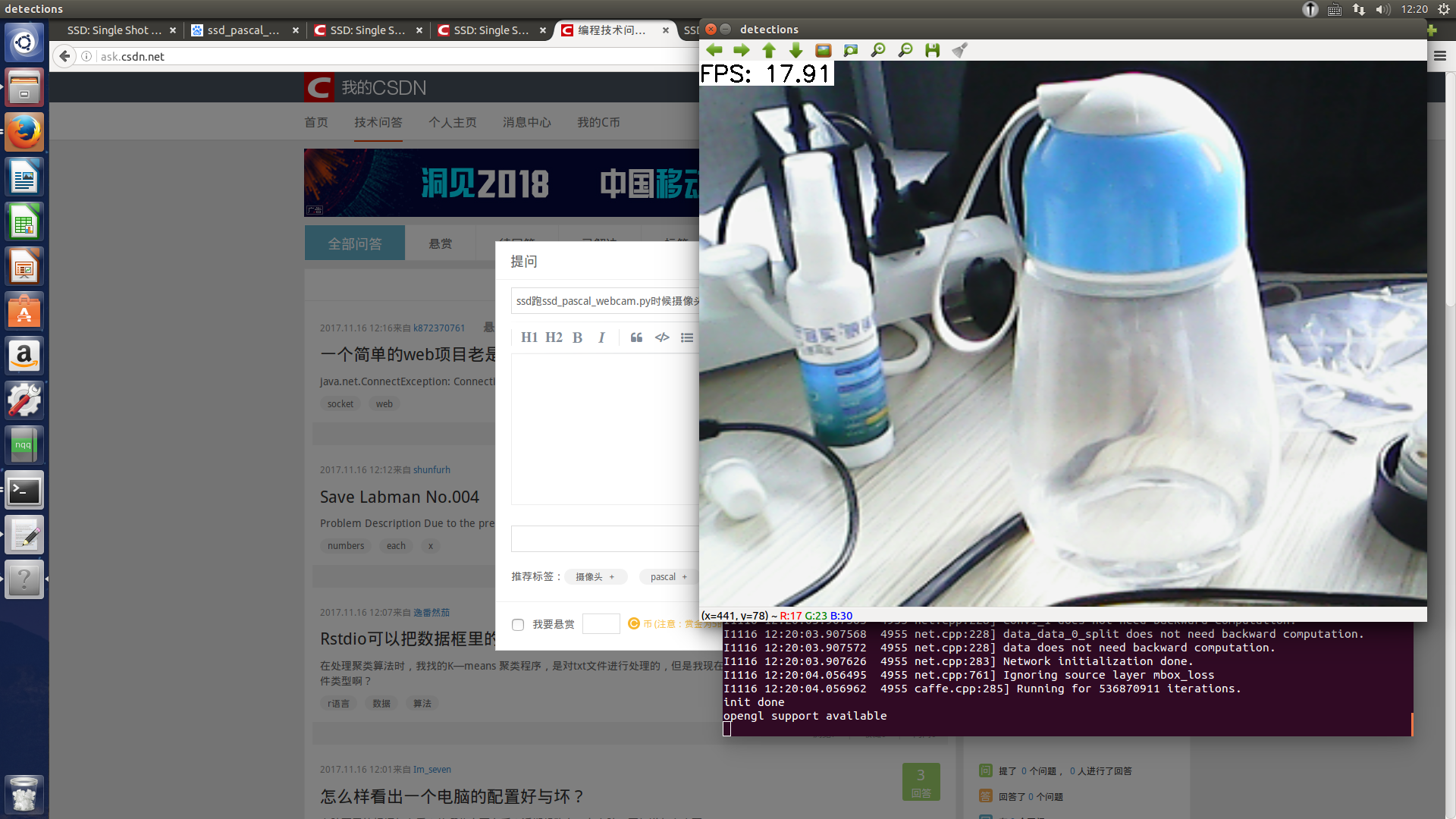
如图所示,这样是什么问题啊,跑的是作者给的例子,
from future import print_function
import caffe
from caffe.model_libs import *
from google.protobuf import text_format
import math
import os
import shutil
import stat
import subprocess
import sys
Add extra layers on top of a "base" network (e.g. VGGNet or Inception).
def AddExtraLayers(net, use_batchnorm=True, lr_mult=1):
use_relu = True
# Add additional convolutional layers.
# 19 x 19
from_layer = net.keys()[-1]
# TODO(weiliu89): Construct the name using the last layer to avoid duplication.
# 10 x 10
out_layer = "conv6_1"
ConvBNLayer(net, from_layer, out_layer, use_batchnorm, use_relu, 256, 1, 0, 1,
lr_mult=lr_mult)
from_layer = out_layer
out_layer = "conv6_2"
ConvBNLayer(net, from_layer, out_layer, use_batchnorm, use_relu, 512, 3, 1, 2,
lr_mult=lr_mult)
# 5 x 5
from_layer = out_layer
out_layer = "conv7_1"
ConvBNLayer(net, from_layer, out_layer, use_batchnorm, use_relu, 128, 1, 0, 1,
lr_mult=lr_mult)
from_layer = out_layer
out_layer = "conv7_2"
ConvBNLayer(net, from_layer, out_layer, use_batchnorm, use_relu, 256, 3, 1, 2,
lr_mult=lr_mult)
# 3 x 3
from_layer = out_layer
out_layer = "conv8_1"
ConvBNLayer(net, from_layer, out_layer, use_batchnorm, use_relu, 128, 1, 0, 1,
lr_mult=lr_mult)
from_layer = out_layer
out_layer = "conv8_2"
ConvBNLayer(net, from_layer, out_layer, use_batchnorm, use_relu, 256, 3, 0, 1,
lr_mult=lr_mult)
# 1 x 1
from_layer = out_layer
out_layer = "conv9_1"
ConvBNLayer(net, from_layer, out_layer, use_batchnorm, use_relu, 128, 1, 0, 1,
lr_mult=lr_mult)
from_layer = out_layer
out_layer = "conv9_2"
ConvBNLayer(net, from_layer, out_layer, use_batchnorm, use_relu, 256, 3, 0, 1,
lr_mult=lr_mult)
return net
Modify the following parameters accordingly
The directory which contains the caffe code.
We assume you are running the script at the CAFFE_ROOT.
caffe_root = os.getcwd()
Set true if you want to start training right after generating all files.
run_soon = True
The device id for webcam
webcam_id = 0
Number of frames to be skipped.
skip_frames = 0
The parameters for the webcam demo
Key parameters used in training
If true, use batch norm for all newly added layers.
Currently only the non batch norm version has been tested.
use_batchnorm = False
num_classes = 21
share_location = True
background_label_id=0
conf_loss_type = P.MultiBoxLoss.SOFTMAX
code_type = P.PriorBox.CENTER_SIZE