正则表达式匹配空行前的所有东西?
用的python的re,有一段文本, 我想匹配第一个\n\n之前的所有东西,包括\n包括文字。试了很多方法不是全部删掉,就是只删了\n\n的上一行
string pattern = txtBiaoDaShi.Text;
pattern = "(\n\n)";
Regex reg = new Regex(pattern);
string input = "hello1" + "\n" + "hello2" + "\n\n" + "word";
bool d = reg.IsMatch(input);
if (reg.IsMatch(input))
{
var t = reg.Matches(input);
Match oneMatch = reg.Match(input);
int index = oneMatch.Index;
var tt = input.Substring(0, index);
}
tt的结果是:hello1\nhello2
.* 匹配不到\n ,要使用[\s\S]*
import re
a="""123
123
123
333
333
"""
p=re.compile("([\s\S]*?)\n\n")
m=p.match(a)
print(m.group(1))
审题不认真,没看到是python
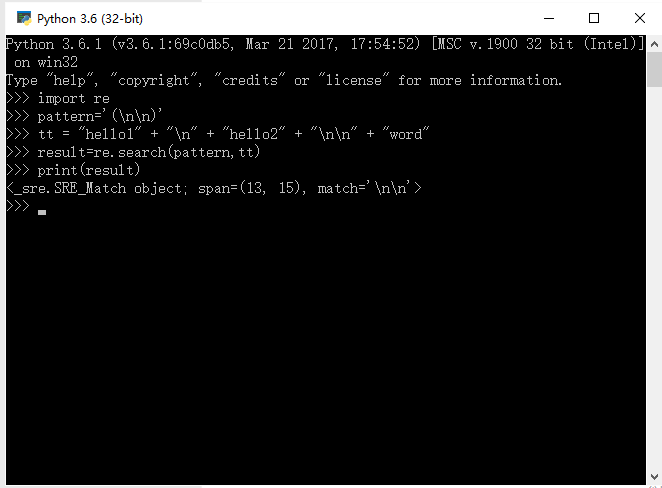
import re
pattern='(\n\n)'
tt = "hello1" + "\n" + "hello2" + "\n\n" + "word"
result=re.search(pattern,tt)
print(result)
这是语句,另外贴个网址:http://www.cnblogs.com/tina-python/p/5508402.html
这个是我搜索的一个网页,我觉得写的很好你可以看看,不过他用的不知道是python哪个版本,有些语句可能不一样。
以下是运行结果
虽然提问的时间比较久远了 但是我试出来了 还是希望帮助到后面搜这个题的人
先造一个串
# -*- coding: UTF-8 -*-
import re
txt = 'hello\nhello2\n\nhello3'
print(txt)
匹配\n\n前面的所有内容
注意使用re.S(匹配包括换行在内的所有字符) re.search()的作用是:扫描整个字符串并返回第一个成功的匹配
# -*- coding: UTF-8 -*-
import re
txt = 'hello\nhello2\n\nhello3'
content = re.search(r'(.*)\n\n',txt,re.S).group(1)
print(content)这是结果

如果匹配\n\n后面的所有内容
# -*- coding: UTF-8 -*-
import re
txt = 'hello\nhello2\n\nhello3'
content = re.search(r'\n\n(.*)',txt,re.S).group(1)
print(content)结果
