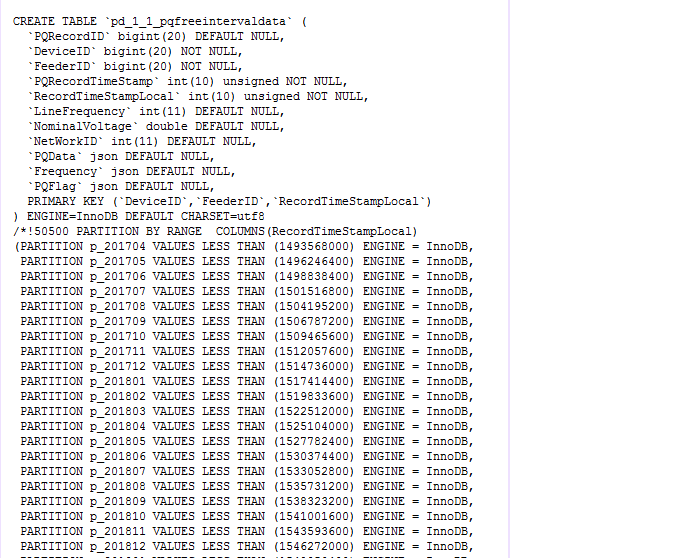
mysql 百万数据查询缓慢怎么解决 已经分区,并且主键索引. 求解决
mysql数据库, 引擎是innoDB,但是查询时间还是很慢, 有的已经达到30s, 找不到问题所在,求大神指点,这是查询代码,并无连表什么的, 分区是按月分的,只6月份的数据文件大小就22G,请问这个是问题出在哪里了?
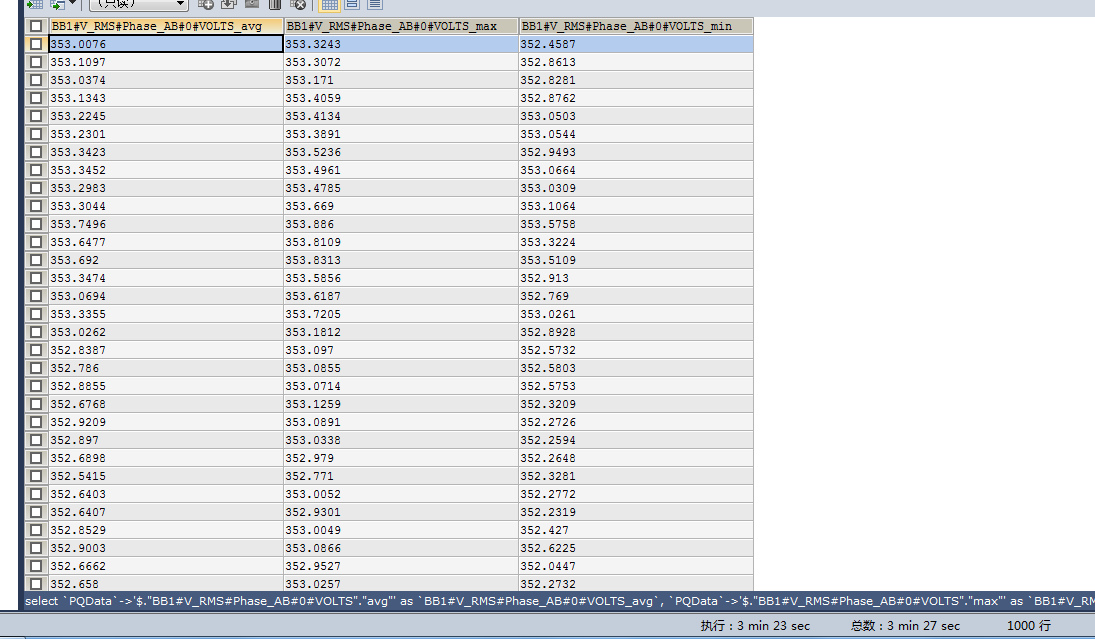
SELECT `PQData`->'$."BB1#V_RMS#Phase_AB#0#VOLTS"."avg"' AS `BB1#V_RMS#Phase_AB#0#VOLTS_avg`, `PQData`->'$."BB1#V_RMS#Phase_AB#0#VOLTS"."max"' AS `BB1#V_RMS#Phase_AB#0#VOLTS_max`, `PQData`->'$."BB1#V_RMS#Phase_AB#0#VOLTS"."min"' AS `BB1#V_RMS#Phase_AB#0#VOLTS_min` FROM `pd_1_1_pqfreeintervaldata` WHERE `DeviceID` = 9 AND `RecordTimeStampLocal` BETWEEN 1494239850 AND 1498732650
附图:
换成>= <=
SELECT `PQData`->'$."BB1#V_RMS#Phase_AB#0#VOLTS"."avg"' AS `BB1#V_RMS#Phase_AB#0#VOLTS_avg`, `PQData`->'$."BB1#V_RMS#Phase_AB#0#VOLTS"."max"' AS `BB1#V_RMS#Phase_AB#0#VOLTS_max`, `PQData`->'$."BB1#V_RMS#Phase_AB#0#VOLTS"."min"' AS `BB1#V_RMS#Phase_AB#0#VOLTS_min` FROM `pd_1_1_pqfreeintervaldata` WHERE `DeviceID` = 9 AND `RecordTimeStampLocal` >= 1494239850 AND `RecordTimeStampLocal`<=1498732650
另外补充下,其实你单纯查一个大表,用索引字段=xxx 获取结果还是很快的,但是如果count(1) 结果非常大。肯定就会非常慢
把between and 改成>=and<=这样试试
mysql count(1)的机智是不会走任何索引的,对于量非常多的数据表生成统计类的信息,目前来说有3种推荐的方法提升效率。
第一提升硬盘的IO效率。因为他要扫符合条件的这个表。第二个是建立表视图。把关键的统计项创建成视图,但是不太推荐这种做法,因为视图会直接降低基础
表的读写效率。第三种是mysql+hadoop,分布式利用集群来提升mysql本身的效率。
本身mysql就是存在你说的这个问题。所以别研究从数据库本身或者sql本身去解决他了。
mysql 不是自带有高效查询么?我们查询2百万的数据都要不到一秒 推荐你研究下http://www.jb51.net/article/31868.htm