同样的代码在Java项目可以运行但是在webproject就不行
String url = "https://suggest.taobao.com/sug?code=utf-8&callback=abc&q=水杯";
doc = Jsoup.connect(url).ignoreHttpErrors(true).timeout(100000).get();
Elements em1 = doc.getElementsByTag("body");
System.out.println(doc);
String str = em1.toString();
就是上面这段代码 在javaproject里面可以获取我想要的结果 但是放在webproject里面就得不到结果了,有没有大佬指点一下这是什么情况啊? 怎么解决啊
这个URL的返回结果是一段纯文本,且不存在body节点啊,doc.getElementsByTag("body");应该没有内容才对啊。。
这段代码在你说的两种环境中分别都有什么输出?

这个是在javaproject里运行的结果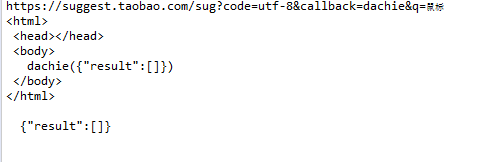
这个是发布过后的运行结果
刚刚研究了一下Jsoup,我认为这个场景下你的用法有点奇怪,首先,这个URL的返回结果就是纯文本,你的目的也是拿到这个字符串,但是你调用的是get()方法,拿到了Document,这样Jsoup就必须做了多余的一步,就是把这个返回的字符串包装成规范的HTML,把请求结果封装在<body></body>里面。然后你从Document里面获取节点,然后获取内容。
我不知道什么原因真正导致了你的问题,但是这样确实不是好的办法,因为转换来转换去说不定哪一步就出了问题。
我只是推荐你的改成这样的写法:
String res = Jsoup.connect(url).ignoreHttpErrors(true).timeout(100000).execute().body();
这样直接拿到了请求的返回结果,直接就是一个字符串,这样应该在任何平台上都是统一的了,你可以改一下相应的逻辑试一试。
刚刚试了一下你说的方法 但是返回来的结果还是没有值,我觉得这个问题和我写的方法是没有太大的关系的吧