一道ACM试题,求大神解答,如果有代码就更好了

#include<iostream>
#include<stack>
using namespace std;
int main(){
int n;
while(cin>>n,n){
stack<int> p;
for (int i = 0; i < n;++i) {
int num;
cin >> num;
if(p.empty()){
p.push(num);
}
else if(p.top()!=num){
p.pop();
}
else if(p.top()==num){
p.push(num);
}
}
cout << p.top() << endl;
}
}
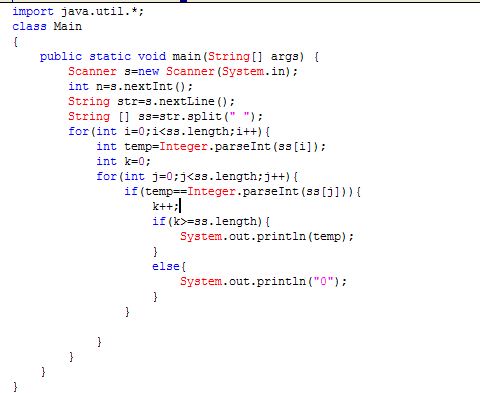
哥们差不多就是这样的,还差点微调,你自己调试下,我要上课;了
这个只是一组的情况,题目要求是500组的样子,加油吧
考慮到時間複雜度,我們不能一個個判斷,可以借鑒編程之美中的算法,回去給你寫一下
这个要500组,O(N)的算法就已经 有5亿了,不知道时间限制多少,我看到题目后想到了O(NLOGN)的算法,就是对于一组数排序后,很自然的得到众数了,还有不知道这个题的内存限制,如果内存给你够大的话,用散列表可以做到O(N)的时间,但是空间辅助度要到O(M)这里的M是数的取值范围,在这道题中都是一样,PS这个出题太不正规了。。。
#include<iostream>
#include<vector>
using namespace std;
int Find(int *ID, int n){
int nTimes = 0, candidate;
for (int i = 0; i < n; i++) {
if (nTimes == 0) {
candidate = ID[i];
nTimes = 1;
}
else {
if (candidate == ID[i]) {
nTimes++;
}
else {
nTimes--;
}
}
}
return candidate;
}
void Print(vector<int> &v) {
vector<int>::iterator m;
for(m = v.begin(); m != v.end(); m++) {
cout<<*m<<endl;
}
}
int main() {
int n;
int *A;
vector<int> v;
cin>>n;
while(n!=0) {
A=new int[n];
for(int i=0;i<n;i++) {
cin>>A[i];
}
v.push_back(Find(A,n));
delete []A;
cin>>n;
}
Print(v);
return 0;
}
/*
5
1 2 3 3 3
6
2 1 1 1 5 1
7
3 5 7 5 5 10 5
0
*/

兄弟,怎么样呀,可以吗,满足你的要求吗
利用分治算法可以解决这个问题,首先考虑物品数目为偶数的情况,将物品两两进行分组比较,如果两个元素相等,那么就讲一个元素放到筛选后的数组B内,否则把数字全部抛出,然后再对B数组进行同样的分组操作,最后剩下一个元素直接检查其在数组中的出现次数,如果次数大于n/2就是所选的答案,否则没有答案
#include
#include
using namespace std;
int main(){
int n;
while(cin>>n,n){
stack p;
for (int i = 0; i < n;++i) {
int num;
cin >> num;
if(p.empty()){
p.push(num);
}
else if(p.top()!=num){
p.pop();
}
else if(p.top()==num){
p.push(num);
}
}
cout << p.top() << endl;
}
}
原来是求一组数据里出现次数超过一半的那个数啊