python爬虫网站信息乱码问题
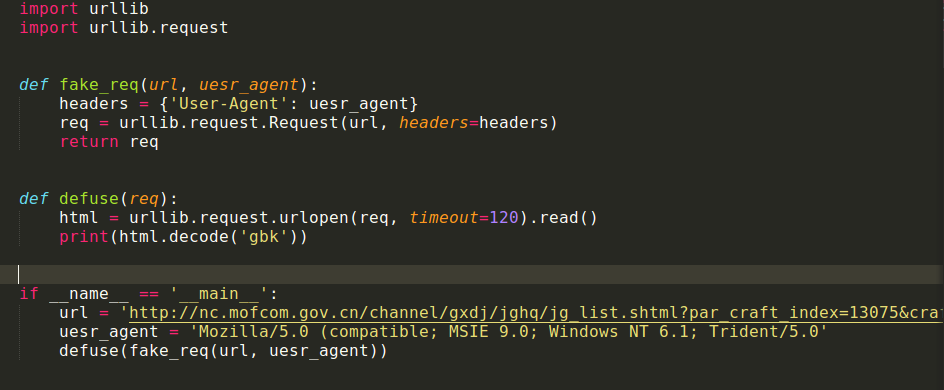
uesr_agent = 'Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0'
headers = {'User-agent':uesr_agent}
req = urllib.request.Request(url, headers = headers)
html_1 = urllib.request.urlopen(req, timeout=120).read()
#html = str(response.read(),'utf-8')
encoding_dict = chardet.detect(html_1)
#print encoding
web_coding = encoding_dict['encoding']
print (web_coding)
if web_coding == 'utf-8' or web_coding =='UTF-8':
html = html_1
else:
html = html_1.decode('gbk','ignore').encode('utf-8')
print (html)
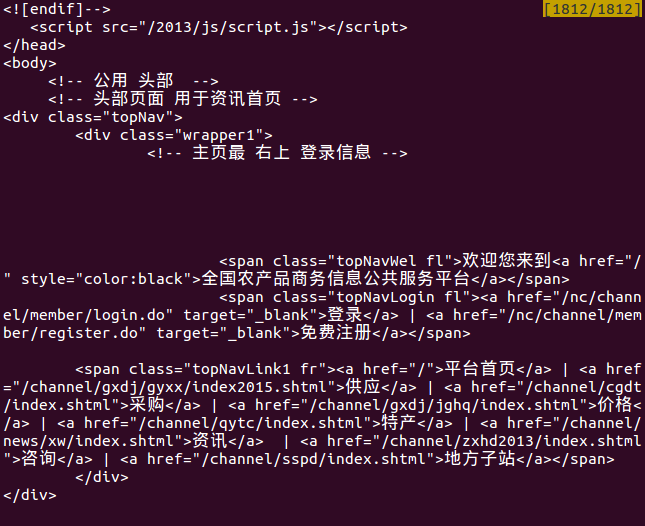
网站地址:
http://nc.mofcom.gov.cn/channel/gxdj/jghq/jg_list.shtml?par_craft_index=13075&craft_index=20413&startTime=2014-01-01&endTime=2014-03-31&par_p_index=&p_index=&keyword=&page=1
显示信息:
用的python3,把网上的方法都试了一遍,还是不行,不知道怎么办了,求助
对应内容UTF8编码处理一下
In [5]: s = "\xe4\xbb\xb7\xe6\xa0\xbc\xe8\xa1\x8c\xe6\x83\x85".decode('utf8')
In [6]: s
Out[6]: u'\u4ef7\u683c\u884c\u60c5'
In [7]: print(s)
价格行情
放弃chardet吧,直接用 gbk 来解码.