python requests.get(url) 采集网页中文乱码问题。
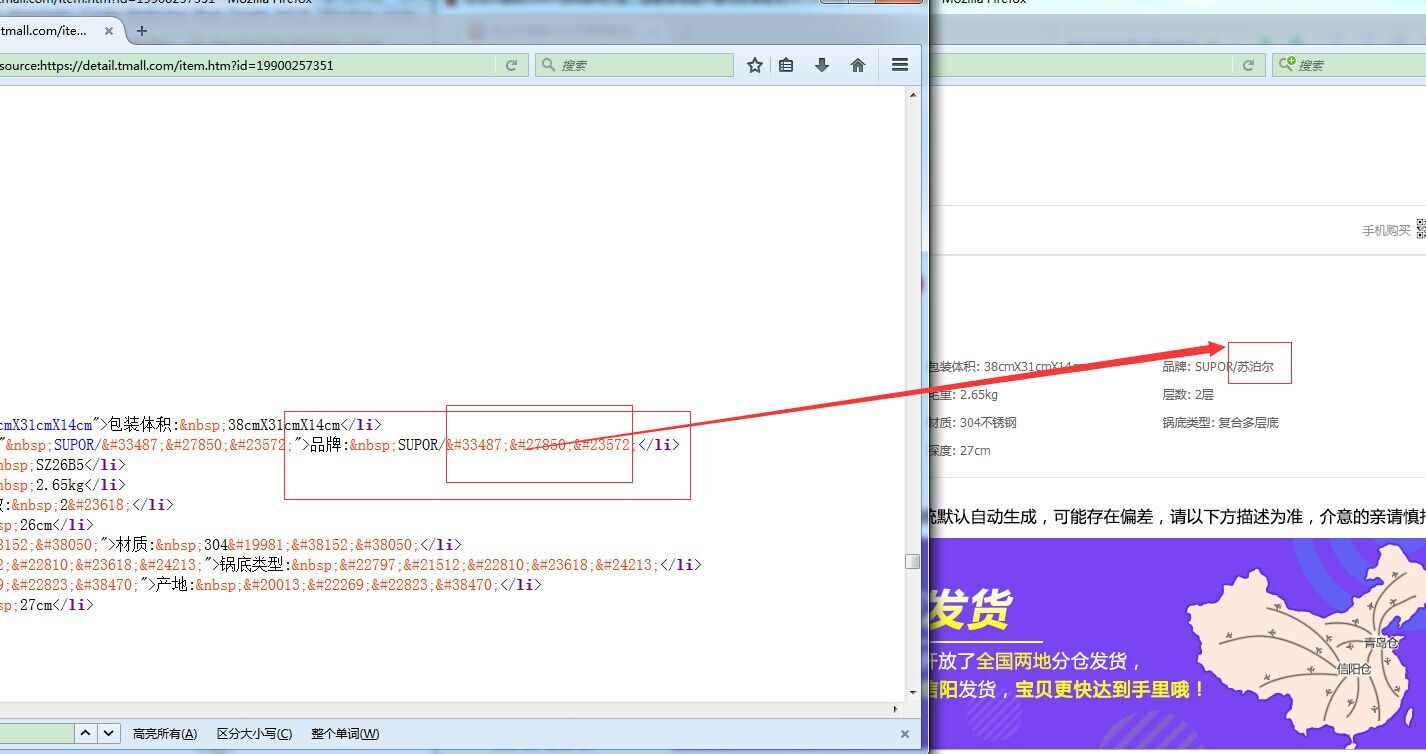
如图:这个编码怎么解决,
看下编码是不是gbk,设置一下编码,
http://cn.python-requests.org/zh_CN/latest/
不要动不动就是“乱码”,这是就是HTML中合法的转义。苏表示这个字符的 Unicode 就是 33487,对应字符就是苏。
被/弄成转义代码了而已。解决方法就是在苏和斜杠中间加个空格 或者使用转义码来解决。望采纳。
read()后加解码即可。decode(utf-8)解码为utf-8格式,有的html也为gbk格式
我已经搞定了,,,,,
如何搞定的?我也遇见这个问题了