用正则表达式匹配网页<th>标签内的文字内容
想写个爬虫脚本将“http://db.yaozh.com/instruct”中的药品信息爬下来,现在我需要用正则表达式来匹配以下的html内容,跪求。。。
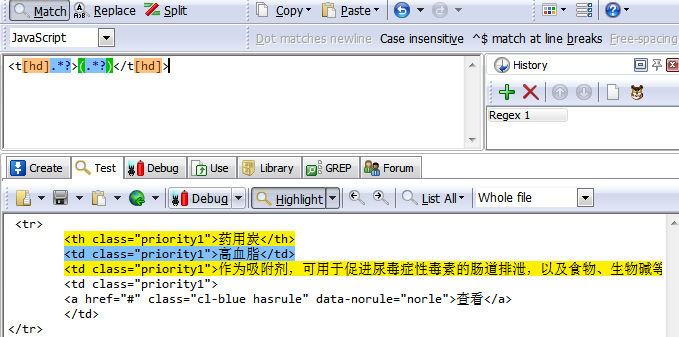
<tr>
<th class="priority1">药用炭</th>
<td class="priority1">高血脂</td>
<td class="priority1">作为吸附剂,可用于促进尿毒症性毒素的肠道排泄,以及食物、生物碱等中毒及腹泻、腹胀</td>
<td class="priority1">
<a href="#" class="cl-blue hasrule" data-norule="norle">查看</a>
</td>
</tr>
<th class="priority1">([\s\S]+?)</th>
可以先把
....匹配出来,然后把html标签去掉么。。reg="
(.*?)".希望能帮到你。如果是Python的话,用BeautifulSoup多好,简单方便。
http://beautifulsoup.readthedocs.io/zh_CN/latest/
(.*?)
<th class="priority1">(.*?)</th>