求助,python 解析爬取的网页源码中的json部分
爬下来的网页源码有一部分是这样的 :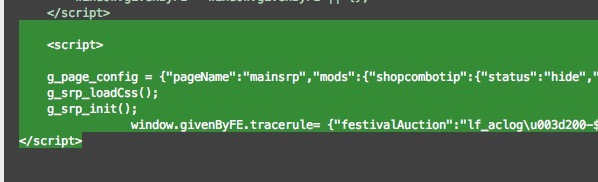
中间那一部分是json吧?要怎么才能解析成像浏览器那样的好继续抓取所要的信息?
说部分是因为有另外一些是正常的html,就中间这一部分想要的信息就这样两行超级长的延伸。。。也使用过json.load()来解析,不想显示错误“没有可以解析的json对象”。
这两行中还有一部分“}\u0026nick\u003d${nick}\u0026rn\u003d${rn}\u0026stats...”应该是unicode的编码,也不知道要怎么办。。
我是想要从淘宝上爬些衣服的图片下来,从首页开始,爬出其中分页的链接,然后拿到分页的源码后要解析出图片的url时出的问题。
下面是部分代码:
url = 'https://www.taobao.com'
header = {'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_3) AppleWebKit/601.4.4 (KHTML, like Gecko) Version/9.0.3 Safari/601.4.4'}
cookie = {"cookies":'mt="ci=10_1";uc1="cookie14=UoWyia%2Bf0iS5lw%3D%3D&cookie16=VT5L2FSpNgq6fDudInPRgavC%2BQ%3D%3D&existShop=false&cookie21=U%2BGCWk%2F7pY%2FF&tag=7&cookie15=UIHiLt3xD8xYTw%3D%3D&pas=0"'}
html = requests.get(url)
#解析html,xml转义字符
html_parser = HTMLParser.HTMLParser()
text = html_parser.unescape(html.text)
soup = BeautifulSoup(html.text)
#用xpath来提取链接,如"打底羊毛衫"这个类别
selector = etree.HTML(text)
sub_url = selector.xpath('//*[@id="J_Top"]/div/div[1]/div/div/div/div[3]/div[1]/div/div/div[1]/a[1]/@href')
print sub_url[0]
sub_html = requests.get(sub_url[0])
sub_text = html_parser.unescape(sub_html.text)
soup = BeautifulSoup(sub_html.text,"lxml")
print soup.prettify()
print sub_text
sum:
其实方法一直就在那,只是自己懒,怕麻烦不去尝试。。。。
上面知道是json又不敢确定的时候,只用了json.load(html.text)尝试,提示没有json object就一直再乱搜,其实也知道有一部分不是json,只有只要信息的那一部分是json,应该按一开始的想法截取出来再解析。不要怕麻烦,不要懒--!
将是json部分解析出来:
想要一次截取到准确要的部分比较难->观察是在一个标签里的->先把所有的被这个标签包围的部分findall->找出是是json的部分->只要其中一部分,但re要选取刚好这一部分困难->取前取尾,再把尾补上->
ontent = re.findall('g_page_config = (.*)"map":{}};',s[2],re.S)
js = content[0] + '"map":{}}'
->截出来后对里面的unicode编码非常苦恼,一直死磕,其实不必,应该先分析这个dict的结构(可以打印这个dict来分析里面到底有几个元素,当然要先把json解析为dict):
import json
jsdata = json.loads(js)
->一层一层打印分析哪个元素里是包含图片地址的->最后是一个list->找出jpg地址->下载
我用re把json的部分截取出来了,也用json.loads()解析成了字典,现在的问题是里面需要的信息那部分是有一些是unicode 编码的,求解。。。。
{"pageName":"mainsrp","mods":{"shopcombotip":{"status":"hide","export":false},"shopstar":{"status":"hide","export":false},"navtablink":{"status":"hide","export":false},"personalbar":{"status":"show","data":{"metisData":{"nickname":"","query":"秋季打底衫","shopItems":[{"text":"黄钻爱买店铺","count":"500+","url":"/search?q\u003d秋季打底衫\u0026tab\u003dmysearch\u0026filter_rectype\u003d44\u0026stats_click\u003dms_from:44","trace":"metis44"},{"text":"回头客爱买店铺","count":"500+","url":"/search?q\u003d秋季打底衫\u0026tab\u003dmysearch\