python3写的登陆知乎爬虫出错
import gzip
import re
import http.cookiejar
import urllib.request
import urllib.parse
def ungzip(data):
try: # 尝试解压
print('正在解压.....')
data = gzip.decompress(data)
print('解压完毕!')
except:
print('未经压缩, 无需解压')
return data
def getXSRF(data):
cer = re.compile('name="_xsrf" value="(.*)"', flags = 0)
strlist = cer.findall(data)
return strlist[0]
def getOpener(head):
# deal with the Cookies
cj = http.cookiejar.CookieJar()
pro = urllib.request.HTTPCookieProcessor(cj)
opener = urllib.request.build_opener(pro)
header = []
for key, value in head.items():
elem = (key, value)
header.append(elem)
opener.addheaders = header
return opener
header = {
'Connection': 'Keep-Alive',
'Accept': 'text/html, application/xhtml+xml, */*',
'Accept-Language': 'en-US,en;q=0.8,zh-Hans-CN;q=0.5,zh-Hans;q=0.3',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; WOW64; Trident/7.0; rv:11.0) like Gecko',
'Accept-Encoding': 'gzip, deflate',
'Host': 'www.zhihu.com',
'DNT': '1'
}
url = 'http://www.zhihu.com/'
opener = getOpener(header)
op = opener.open(url)
data = op.read()
data = ungzip(data) # 解压
_xsrf = getXSRF(data.decode())
url += 'login'
id = '这里填你的知乎帐号'
password = '这里填你的知乎密码'
postDict = {
'_xsrf':_xsrf,
'email': id,
'password': password,
'rememberme': 'y'
}
postData = urllib.parse.urlencode(postDict).encode()
op = opener.open(url, postData)
data = op.read()
data = ungzip(data)
print(data.decode())
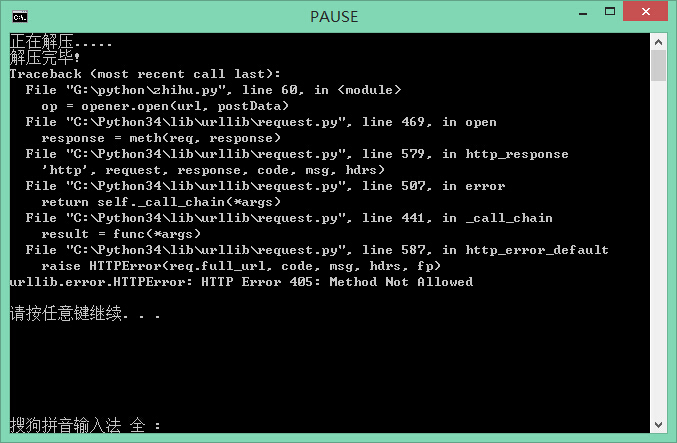
原网址 http://jecvay.com/2014/10/python3-web-bug-series4.html
405 不允许,你的请求方法正确吗? 还是被知乎拦截发现是爬虫了
被知乎拦截了,换个网站试试
你看下知乎现在的登陆地址的字段是多少!还是login么?改下这就好了