Spark on Yarn ShedulerDelay时间怎样优化?
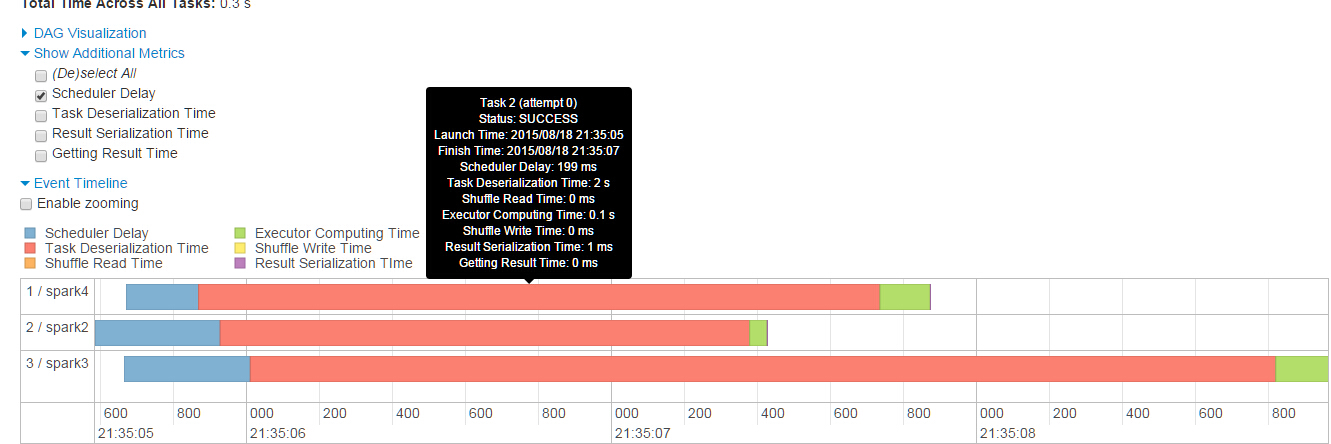
我以yarn-cluster模式执行了SparkPi的例子,用了3个节点,传入的参数(分区数量)也为3
schedulerDelay的解释是从sheduler到executor的Task传输时间,和Task结果从executor到sheduler的传输时间。可以通过减小task的大小和task结果的大小来缩短时间,我不是很理解。
求各位大大解释一下怎样减小task的大小,还有task结果怎样影响的sheduler。
最好能给出一个优化前后的代码和WebUI界面