如何用python剔除特定字符后的所有内容
例如我有一个excel表格,里面的数组含有:
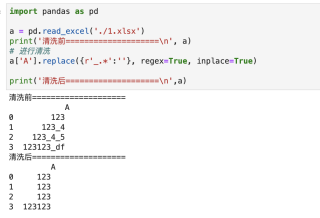
A
123
123_4
123_4_5
123123_df
在这种情况下,如何剔除表格中第一个下划线_后的数字和内容?
目前想到的是用正则表达式,但没有思路如何去做,求教一下
谢谢
##########
感谢下面的回复,我试了试split函数,但是作为dataframe的话会出现error:
AttributeError: 'DataFrame' object has no attribute 'split'
貌似无法量化处理表格形式?
s = input()
result = s.split("_")[0]
print(result)
先自己写一个split函数比如叫df_split
然后调用dataframe的apply方法
def df_split():
.....
return result
# 然后用dataframe的apply方法
train[new_column]=train.apply(df_split,axis=1, result_type='expand')