pdfminer3k 读取杂志的pdf文件字体包缺失和返回text的乱码问题如何解决?
1. 在github上可供下载的字体包没有warning中出现的字体样式,而且字体样式很多是组合式的(详见下图示例)

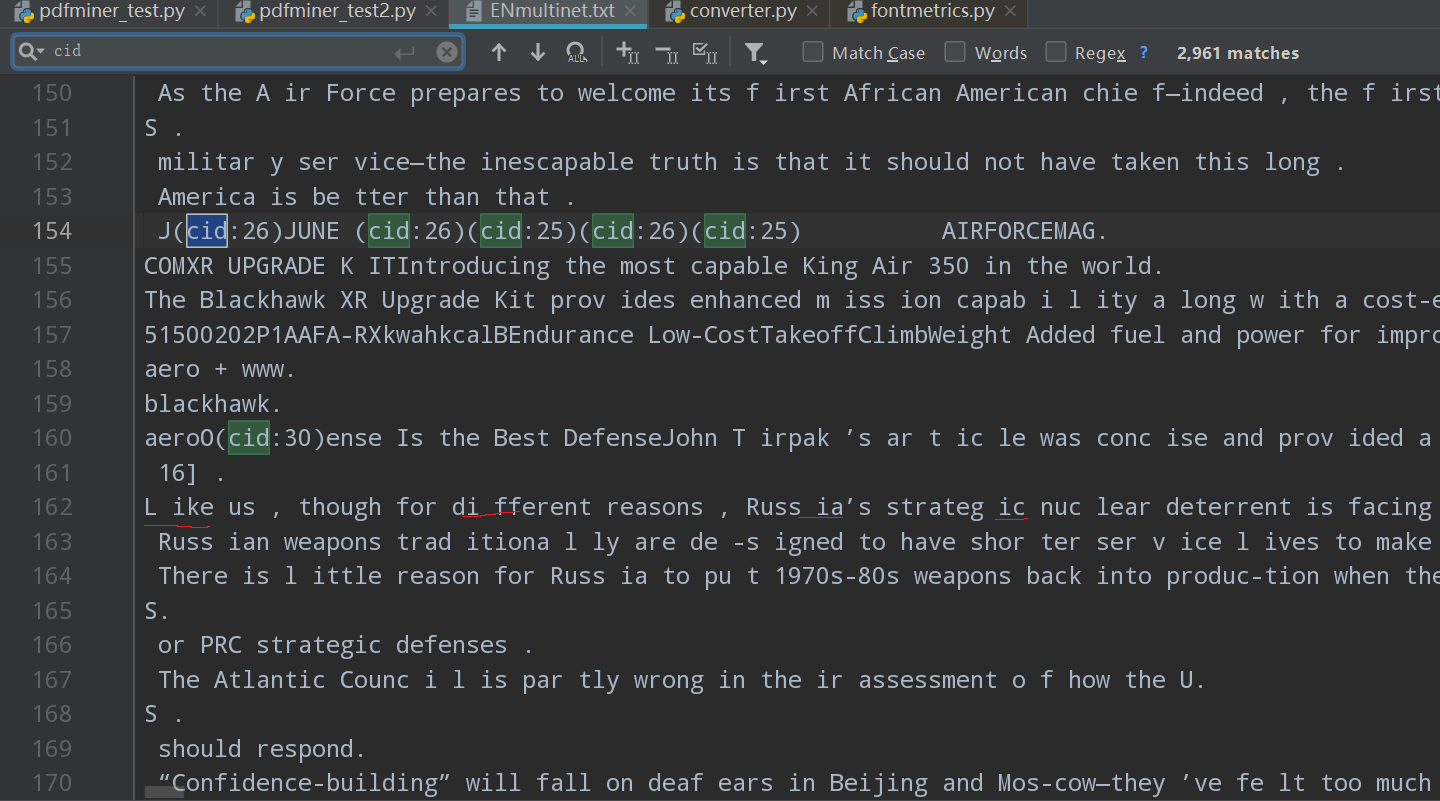
** 2. 返回的text文本中有(cid:数字)形式的“乱码”,但我提取的pdf文件为全英文,目前网上针对此问题主要是与“中文乱码”相关的**
3. 部分英语单词被空格隔开了,怎么解决“识别并删去多余空格,但是不会影响原语句单词之间的空格”这一问题
初步发现遇见“i”就会分隔,如何与“I”做区分,或者加设判断将遇见“i”的分隔还原
(2、3详见下图示例)
warning应该没有什么问题,不影响解析
至于空格,这个思路在于,遍历文本中所有的单词1+空格+单词2
准备一个英文单词表文件
如果单词1单词2中有任意一个在已知词汇列表中没有,并且单词1+单词2有,那么就去掉空格
参考:https://www.cnblogs.com/wzjbg/p/7644127.html
字体库:
https://github.com/euske/pdfminer/tree/2103e5875ef04cfaf424b25d2fd0dc9535a90714/pdfminer/cmap