采取的soup.find方法爬取豆瓣TOP250网站中的电影发行国家和语言![图片说明]
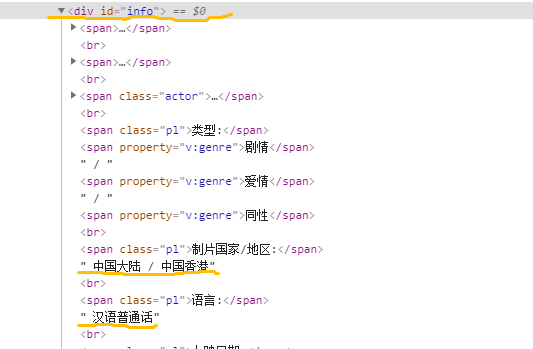
这是相关的网页代码,我发现 中国大陆 / 中国香港 和 汉语普通话 没有对应的标签。不知道该怎么爬下来(https://img-ask.csdn.net/upload/202009/16/1600237171_585173.png)
比如这个是我爬的IMBd链接的代码
IMBdlink = soup.find('div', id='info').find('a',target='_blank')['href']
from bs4 import NavigableString, Comment
#省略
result = soup.find('div', id='info')
for item in result.children:
if isinstance(item, NavigableString) and not isinstance(item, Comment):
cleanItem=item.replace('\n', '').replace('\r', '').strip()
if(cleanItem):
print(cleanItem)
https://blog.csdn.net/weixin_46355013/article/details/107209884
{kind=link}