Mysql查询语句性能分析
问题比较奇怪,本来是做了一个测试环境测试
结果测试环境效率更快,才发现了异常,正式的反而非常慢
这是原始SQL语句
SELECT
c.*
,s.stuf_id
,s.stuf_no
,s.stuf_name
,s.stuf_standard
,s.digi_item_type as stuf_item_type
,sb.stuf_id as stuf_bom_id
,sb.stuf_no as stuf_Bom_no
,sb.stuf_name as stuf_Bom_name
,sb.stuf_standard as stuf_Bom_Standard
from cost c
left join stuff s on c.cost_stuf_id=s.stuf_id
left join stuff sb on c.cost_prod_id=sb.stuf_id
where 1=1 and s.deleted=0 and sb.deleted=0 order by cost_Prod_Id,cost_Sort_No,cost_id
LIMIT 100
正式的速度更慢,基本上等不出来,cost表80万数据,stuff表10万多数据
正式SQL解释

测试SQL解释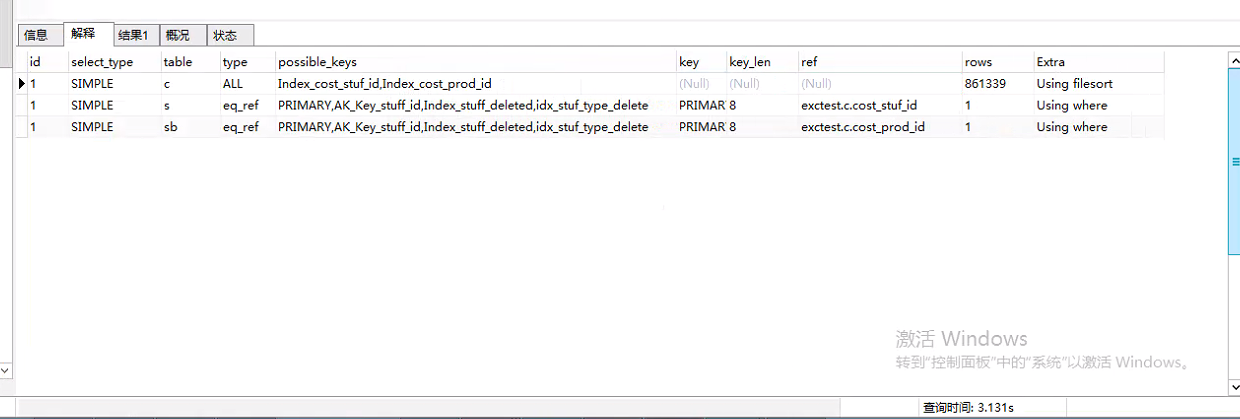
表和表结构,索引都是一样的
测试数据库表结构和数据是从正式库复制过去的吗?
两个数据量一个,结果一样,但是执行计划不同,那应该是由于优化器中采集的数据不一样,从而觉得了使用不同的执行计划。
另外全表扫描比走索引快,那是因为即使使用索引,预估扫描10W行,也就是说可能要伴随10W次随机扫描,而全表是顺序扫描,因此全表的速度比走索引快。
如果你的索引的选择率较高,预估扫描的行较少的话,使用索引会更快些