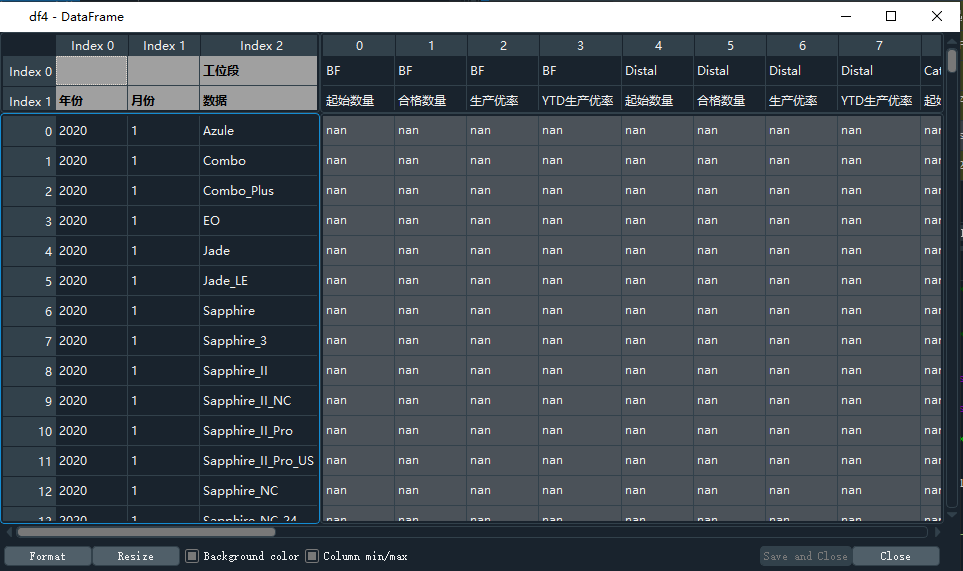
Python中Pandas如何groupby后,更换索引等内容(顺序,层级等),以满足标准模板的要求?
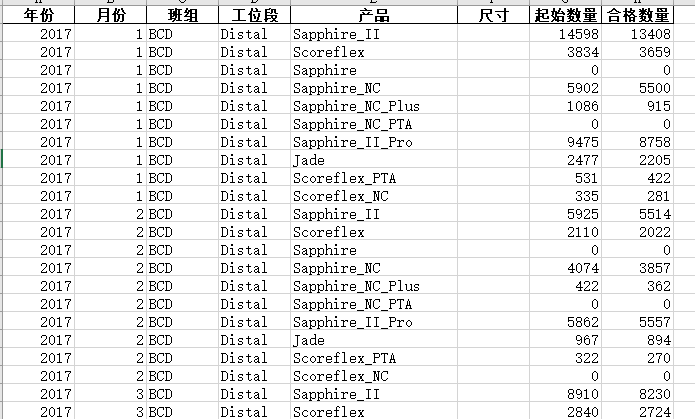
其中原始数据Yield_DB如下:
#conding=utf8
import pandas as pd
import numpy as np
Yield_DB = pd.read_excel(r'C:\Users\sliu\Desktop\Python Coding\Yield_DB.xlsx', sheet_name='Yield_DB')
df3 = Yield_DB.groupby(["年份","月份","产品","工位段"]).sum().unstack()
df4 = pd.DataFrame(columns = pd.MultiIndex.from_product([mile_list,mile_items],names=['工位段','数据']),
index = pd.MultiIndex.from_product([year_list,month_list,product_list],names=["年份","月份","产品"]))
Yield_by_section = pd.concat([df4,df3],axis=1,join='outer',ignore_index='False')
writer = pd.ExcelWriter('Yield_DB.xlsx')
Yield_DB.to_excel(writer,sheet_name='Yield_DB',index=False)
Yield_by_section.to_excel(writer,sheet_name='Yield_by_section',index=True)
writer.save()
df3的样式:
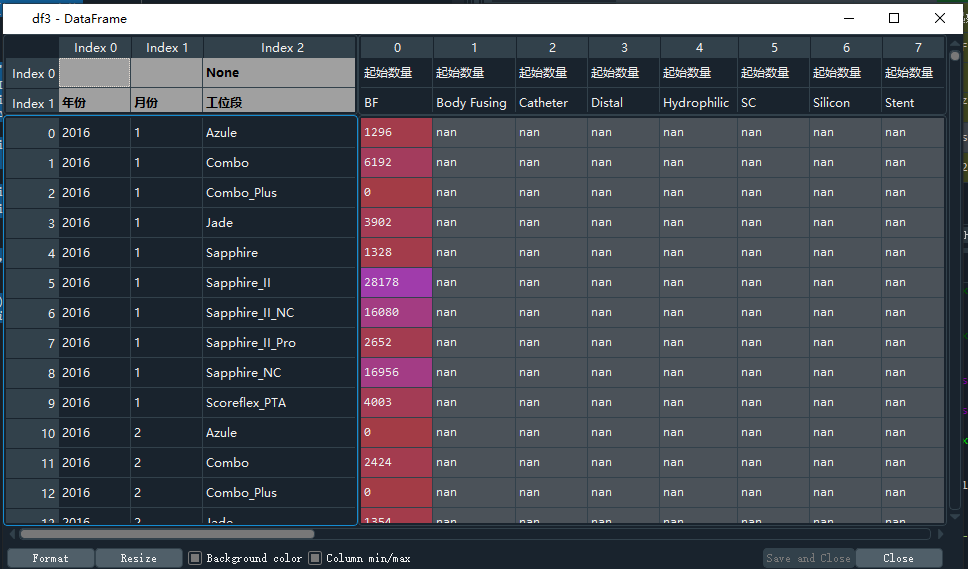
df3和df4行索引一致,但是列索引不一样(顺序,层级),要达到的效果是df4这种样式。 试过了一些合并的方法,但是效果都不理想。