response.xpath返回值不管怎么样都为空怎么解决呀
首先,在xpath helper中如下:
然后是我的代码:
import scrapy
from farfetch.items import FarfetchItem
class DadaqiSpider(scrapy.Spider):
name = 'dadaqi'
# allowed_domains = ['www.xxx.com']
start_urls = ['https://www.farfetch.cn/cn/shopping/women/alexander-mcqueen/items.aspx?page=1&view=90&scale=315']
def parse(self, response):
li_list = response.xpath('//*[@id="slice-container"]/div[3]/div[2]/div[2]/div/div[1]/ul/li')
for li in li_list:
new_url = 'https://www.farfetch.cn/' + li.xpath('./a/@href').extract_first()
detail_url = new_url.replace('<!--', '"').replace('-->', '"')
item = FarfetchItem()
item['detail_url'] = detail_url
yield scrapy.Request(url=detail_url,callback=self.detail_parse,meta={'item':item})
def detail_parse(self,response):
item = response.meta['item']
brand = response.xpath('//*[@id="bannerComponents-Container"]/span/span[1]/a/span/text()').extract_first()
name = response.xpath('//*[@id="bannerComponents-Container"]/span/span[2]/text()').extract_first()
Description = response.xpath('//*[@id="panelInner-0"]/div/div[1]/div[2]/p/text()').extract_first()
part = response.xpath('//*[@id="panelInner-0"]/div/div[2]/div/div[1]/text()').extract_first()
item['brand'] = brand
item['name'] = name
item['Description'] = Description
item['part'] = part
yield item
返回的结果是: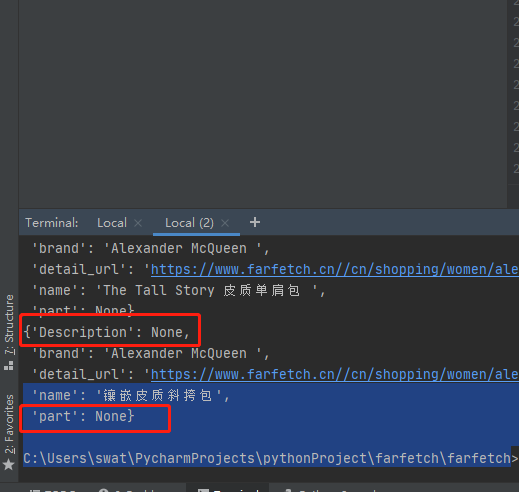
response.text出来的结果是包含我想要的内容: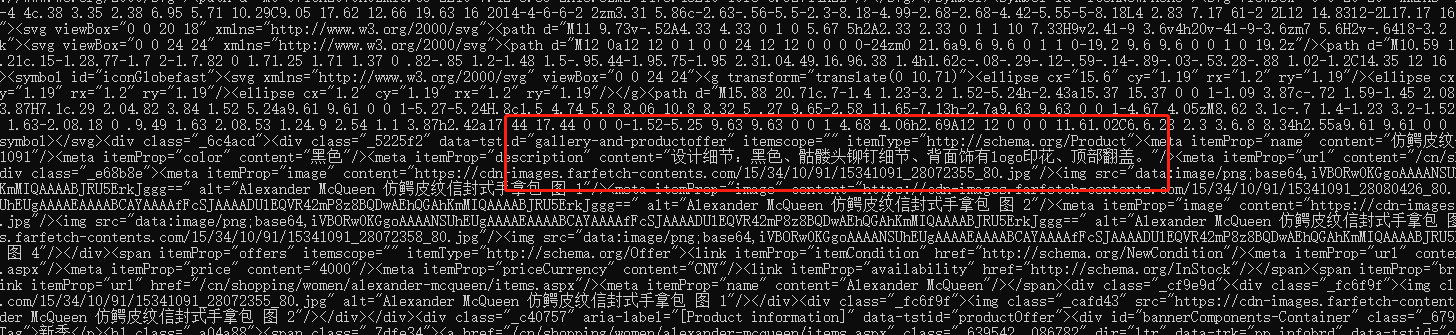
请问这个问题应该怎么解决啊
打印出来你会发现 没有panelInner-0这个节点,你直接requests请求没有这个节点,这个节点不叫这个名字,你可以试试 _3a2fe4 _d85b45这个class属性 (包含关系)以及_94c8ff这个class属性
不要直接用xpath helper ,不准,静态请求的内容和页面动态加载完之后的页面是不一样的