怎么才能不被发现是 脚本 发起的请求?
今天我用java的httpclient访问b站,结果被发现是脚本,然后请求返回的数据都是假的。
我把浏览器访问时的参数都原封不动的带上了,还是被发现了。
下面是java的代码
getMethod.addRequestHeader("cookie", Header.cookie);
//以下是为了不让识别出是脚本额外携带的参数,如果不携带也能获取数据
getMethod.addRequestHeader(":authority","api.bilibili.com");
getMethod.addRequestHeader("method","GET");
getMethod.addRequestHeader(":path","/x/relation/followings?vmid=12345");
getMethod.addRequestHeader(":scheme","https");
getMethod.addRequestHeader("accept","text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9");
getMethod.addRequestHeader("accept-encoding","utf-8");
getMethod.addRequestHeader("accept-language","zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6");
getMethod.addRequestHeader("cache-control","max-age=0");
getMethod.addRequestHeader("sec-fetch-dest","document");
getMethod.addRequestHeader("sec-fetch-mode","navigate");
getMethod.addRequestHeader("sec-fetch-site","none");
getMethod.addRequestHeader("sec-fetch-user","?1");
getMethod.addRequestHeader("upgrade-insecure-requests","1");
getMethod.addRequestHeader("user-agent","Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.105 Safari/537.36 Edg/84.0.522.52");
下面是浏览器的请求标头
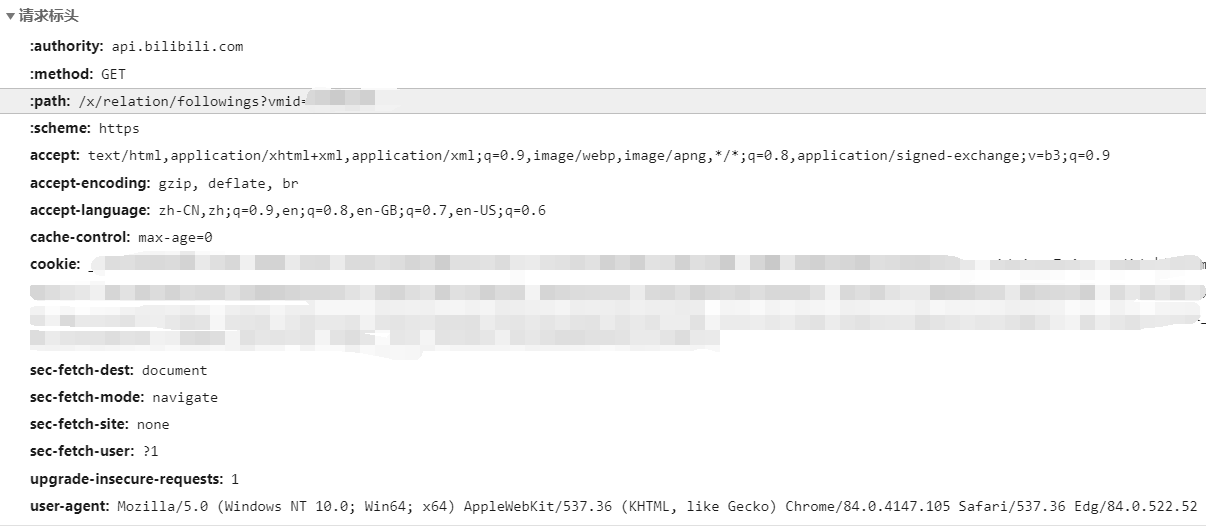
我试了很多遍,还是获得了假的数据,但浏览器请求获得的数据都是真的。
有大佬知道怎么办么?感激不尽!!
现在b站这种级别的,都会有基于机器学习的判别,包括鼠标操作习惯、操作间隔、点击、停留时间、滚动等等,你要做得逼真,你也得用机器学习去训练一个bot。
会不会是在需要先调用其他请求获取一个sign或者token加到cookie中去才能访问呢?之前我爬百度的时候是有这个问题的
先用chrome按正常访问把访问的url顺序、请求参数记录下来,特别注意一些异步的请求。然后再用程序模拟,每次请求之间做一下随机的暂停时间。尽量模拟人为操作
直接请求肯定不行,有些请求参数是动态的,你用固定参数去请求实际已经过期或者无效,返回给你的都是一些静态数据。你可以用selenium模拟整个页面的请求过程,拿到页面数据进行解析