谁能告诉我这是什么sql骚操作?????
最近在做TPCDS测试,可以说是分析型数据库性能测试的最权威标准了。
TPCDS标准测试语句有一个sql是这么写的。
我把它的内容简化一下来看:
我有一张这样的表:
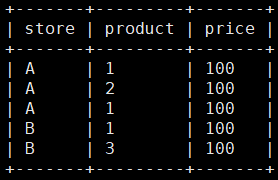
sql是这么写的:
select store ,
product ,
sum(sum(price)) over(partition by product) as price
from tmp2
group by store , product
order by store , product;
最后的结果:
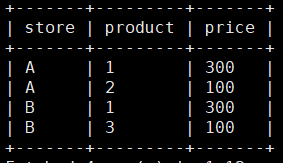
我发现这个sql语句实际的效果是用over函数之后,再去重。
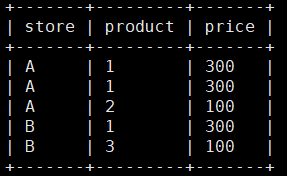
over:
select store ,
product ,
sum(price) over(partition by product) as price
from tmp
order by store , product;
得到:
distinct + over:
select distinct store ,
product ,
price
from
(
select store ,
product ,
sum(price) over(partition by product) as price
from tmp2
) as t
order by store , product;
得到:
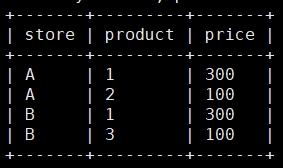
黑人问号脸:
用distinct写不香吗?
为什么写了两层sum()之后,over函数就可以和groupby一起用了??
为什么第二层sum()并不是求和,而是起到了去重的效果???
https://www.cnblogs.com/wshichang/p/10419378.html
这个应该是和SQL语句的执行顺序有关吧,这个SQL的执行顺序是 FROM, GROUP BY ,SELECT ,ORDER BY
首先执行的是查表,然后就是分组了,分组就相当于去重,然后执行SELECT 语句, 最后排序
这个sql 也就是相当于
SELECT STORE,PRODUCT,SUM(PRICE) OVER(PARTITION BY PRODUCT) PRICE
FROM (
select store ,
product ,
sum(price) PRICE
from tmp2
group by store , product ) ORDER BY store , product;
这种机器的sql翻译的确比较奇怪,使用over+group by相当于临时表,比distinct要快一些。