python爬虫使用beautifulsoup的select方法怎么实现相同标签的爬取
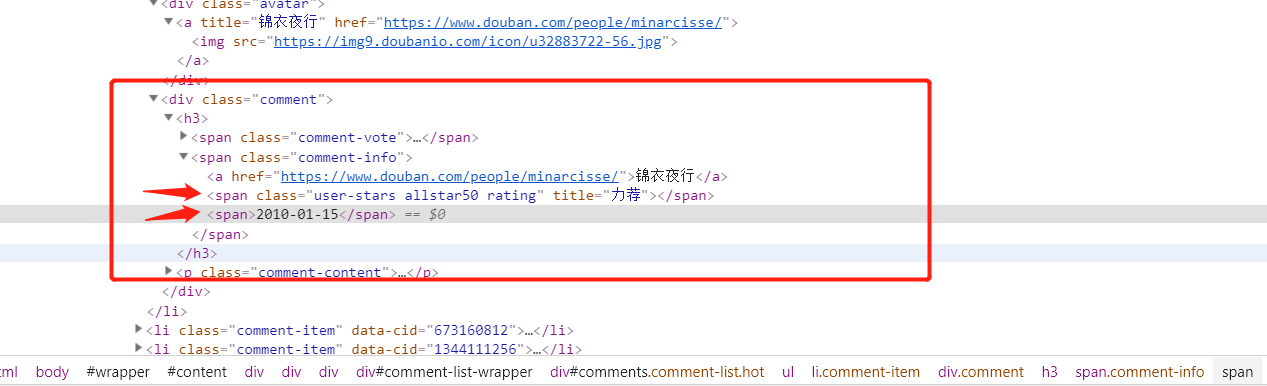
我想爬取这里的第二个span,times = soup.select('.comment .comment-info span')爬出的是第一和第二个span标签,times = soup.select('.comment .comment-info span')[1]只有一个数值。我想把一整页的时间都爬取出来
每本书的class是 comment-item
遍历所有的comment-item,找到class=comment-info下面的span
beautifulsoup4我用的是find,从来没用过select