求问大神python排序问题
有这样一个excel文件
abcd_1 41.39 1.00E-08
abcd_1 32.34 5.00E-08
abcd_1 32.34 5.00E-08
abcd_1 32.34 5.00E-08
abcd_2 45.56 5.00E-08
abcd_2 60.56 3.00E-08
abcd_2 32.53 5.00E-08
abcd_3 58.59 2.00E-08
abcd_3 60.65 1.00E-08
abcd_3 58.59 3.00E-08
abcd_4 34.00 2.00E-18
abcd_4 32.56 2.00E-11
第一列代表不同产品,(比如表中列的四个产品abcd_1,abcd_2,abcd_3,abcd_4),因为来自于不同仓库(数据中没用,就没有在表里列出来),所以名字会有相同。第2列代表评分1,该评分越高越好,第3列代表评分2,该评分越低越好。要根据这两个评分,找到每个产品下评分最优的那一行值,并输出为新的excel。
求问大神,python怎么根据产品名称分组,然后组内排序找到最好的一个,然后把每个产品最好的一个的那一行数据输出到新文件中呢?
import pandas as pd
df = pd.read_excel('product.xlsx',names=['product','score1','score2'],header=None)
df
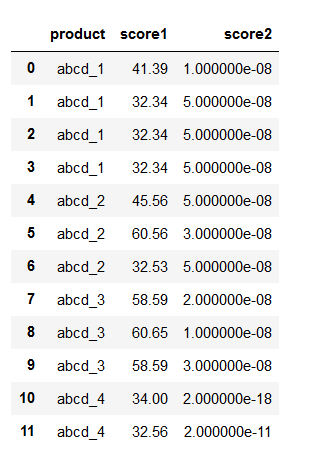
df = df.sort_values(by=['score1','score2'],ascending=[False,True]) #False表示降序排序
df

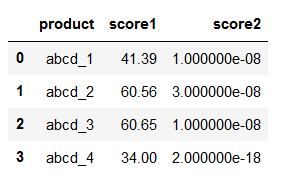
df = df.groupby('product',as_index=False).first()
# as_index=False表示使用原来的索引而不是以分组依据作为索引;first()表示保留第一个数据
df
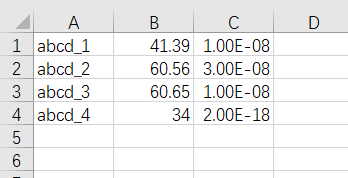
df.to_csv(path_or_buf='result.csv',header=None,index=None)
#headers = None(不保存列名)
#index = None(不保存索引)
如果对你有帮助,请采纳以鼓励。
https://blog.csdn.net/qq_46523755/article/details/105553799
建议使用pandas 和numpy 进行处理!