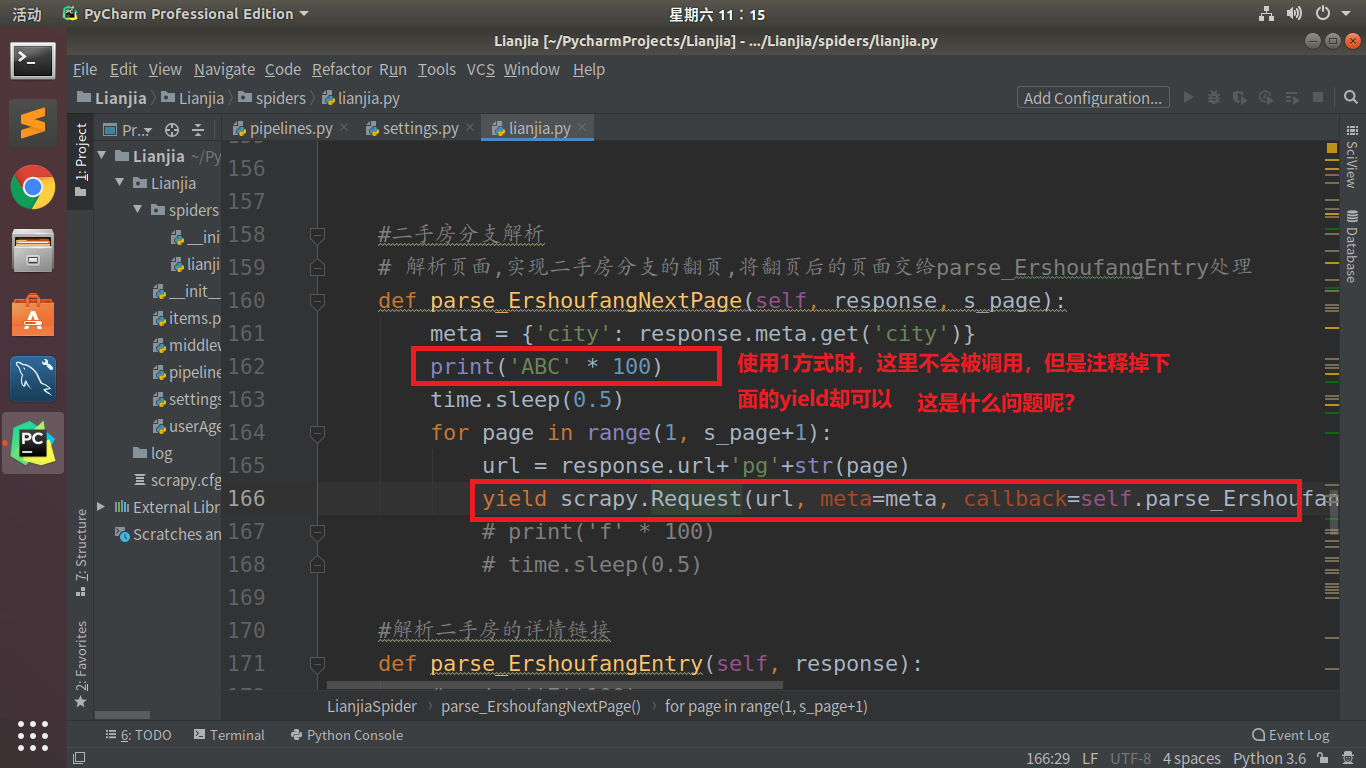
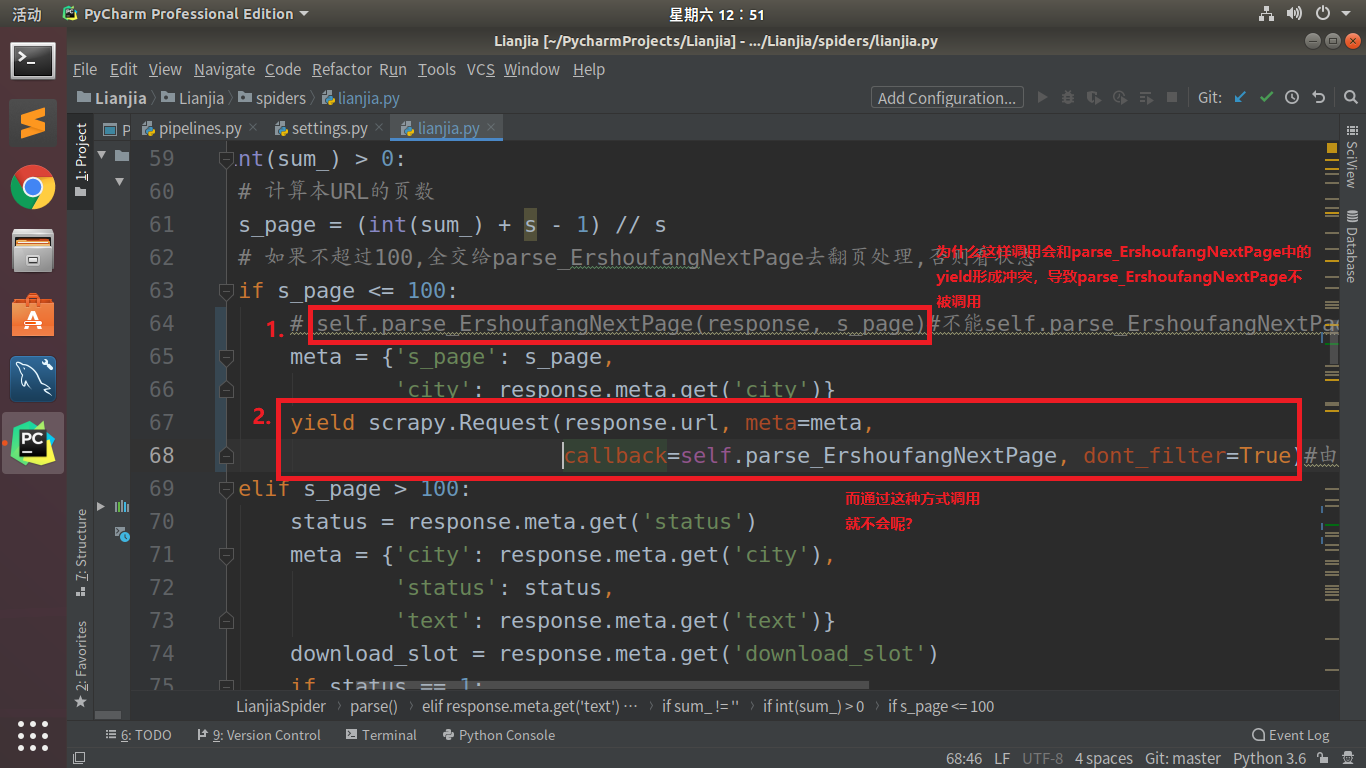
scrapy框架中调用目标解析函数方式:self.fun(response)调用方式和fun中的yield形成阻塞
-*- coding: utf-8 -*-
import scrapy
from Lianjia.items import *
import re
import logging
class LianjiaSpider(scrapy.Spider):
name = 'lianjia'
allowed_domains = ['lianjia.com']
#起始爬取地址,全国的城市页
start_urls = ['https://www.lianjia.com/city/']
def parse(self, response):
if response.url in self.start_urls:
try:
#解析start_urls页的URL,得各城市地址
city_href_list = response.xpath('''//div[@class="city_list"]//li/a/@href''').extract()
city_list = response.xpath('''//div[@class="city_list"]//li/a/text()''').extract()
except IndexError as e:
print('='*80, response.url, 'start_urls的xpath解析出错')
for href, city in zip(city_href_list, city_list):
#携带city下去,并将状态置为0表示为start_urls页面解析的地址发出的请求
meta = {'city': city,
'status': 0}
# 将解析出的各城市地址发请求
yield scrapy.Request(href, meta=meta)
# time.sleep(0.1)
#解析各城市页面,得到二手房,新房等分支的URL
elif response.meta.get('status') == 0:
try:
# 解析各城市页面的页签URL,以建立不同的分支
fr_texts = response.xpath('''//div[@class="nav typeUserInfo"]/ul/li/a/text()''').extract()
fr_hrefs = response.xpath('''//div[@class="nav typeUserInfo"]/ul/li/a/@href''').extract()
except IndexError as e:
print('='*80, response.url, 'floor的xpath解析出错')
meta = {'city': response.meta.get('city'),
'status': 1}
for text, href in zip(fr_texts, fr_hrefs):
meta['text'] = text
# 不全部yield,避免发送不必要的请求,如有开启其他的分支,需在此处开启
fr_list = ['二手房',
# '新房',
]
#匹配地址以什么开头
# if href.startswith('https://.*?www.lianjia.com/erhshoufang'):
if text in fr_list:
yield scrapy.Request(href, meta=meta)
#二手房分支
elif response.meta.get('text') == '二手房':
try:
# 获取本页面每页数据条数
s = len(response.xpath("""//*[@id="content"]/div[1]/ul/li/div[1]/div[1]/a/@href""").extract())
#获取本url总条数
sum_ = response.xpath("""//*[@id="content"]/div[1]/div[@class="resultDes clear"]/h2/span/text()""").extract()[0].strip()
except IndexError as e:
print('='*80, response.url, '每页条数或总条数值的xpath解析出错')
sum_ = ''
if sum_ != '':
if int(sum_) > 0:
# 计算本URL的页数
s_page = (int(sum_) + s - 1) // s
# 如果不超过100,全交给parse_ErshoufangNextPage去翻页处理,否则看状态
if s_page <= 100:
# self.parse_ErshoufangNextPage(response, s_page)#不能self.parse_ErshoufangNextPage调用,会和parse_ErshoufangNextPage的yield冲突,不管后面函数是否回调的当前函数
meta = {'s_page': s_page,
'city': response.meta.get('city')}
yield scrapy.Request(response.url, meta=meta,
callback=self.parse_ErshoufangNextPage,
dont_filter=True
)#由于该地址在之前已经发送过,所以需要dont_filter=True取消URL去重
elif s_page > 100:
status = response.meta.get('status')
meta = {'city': response.meta.get('city'),
'status': status,
'text': response.meta.get('text')}
download_slot = response.meta.get('download_slot')
if status == 1:
#解析city页面,缩小过滤范围,得到区的链接,并发送请求
try:
region_href_list = response.xpath('''//div[@class="position"]/dl[2]/dd/div[1]/div[1]/a/@href''').extract()
except IndexError as e:
print('='*80, response.url, 'if_status1的xpath解析出错')
for href in region_href_list:
url = 'https://' + download_slot + href
meta['status'] = 2
yield scrapy.Request(url, meta=meta)
# return
elif status == 2:
# 解析区页面,得到县的链接,并发送请求
try:
country_href_list = response.xpath('//div[@class="position"]/dl[2]/dd/div/div[2]/a/@href').extract()
except IndexError as e:
print('='*80, response.url, 'if_status2的xpath解析出错')
for href in country_href_list:
url = 'https://' + download_slot + href
meta['status'] = 3
yield scrapy.Request(url, meta=meta)
# return
elif status == 3:
# 解析县页面,得到楼层过滤条件地址并发请求
#..表示选取当前节点的父节点 //div/dl/h2/dt[text()='楼层']/../../dd/a
#a[contains(@href,'NameOnly')]表示选取href中包含NameOnly的a元素
try:
lcs = response.xpath('''//div/dl/h2/dt[text()='楼层']/../../dd/a/@href''').extract()
except IndexError as e:
print('='*80, response.url, 'if_status3的xpath解析出错')
for lc in lcs:
p = re.compile('lc[0-9]/')
lc = p.findall(lc)
url = response.url + lc
meta['status'] = 4
yield scrapy.Request(url, meta=meta)
# return
elif status == 4:
#解析楼层页面, 得到价格过滤条件地址并发请求
try:
ps = response.xpath('''//div/div[2]/dl[1]/h2/dt[text()='售价']/../../dd/a/@href''').extract()
except IndexError as e:
print('=' * 80, response.url, 'if_status4的xpath解析出错')
for p in ps:
meta['status'] = 5
url = 'https://' + download_slot + p
yield scrapy.Request(url, meta=meta)
elif status == 5:
with open('gt100.txt', 'a', newline='\n', encoding='utf-8') as f:
f.write(response.url)
else:
print('if_status溢出'*10, response.url, response.meta, 'if_status溢出'*10)
else:
print('if_s_page溢出'*10, response.url, response.meta, 'if_s_page溢出'*10)
else:
pass
# print('找到总数量sum_为0套,地址:', response.url)
else:
print('if_sum_溢出'*10, response.url, response.meta, 'if_sum_溢出'*10)
else:
print('if分支溢出'*10, response.url, response.meta, 'if分支溢出'*10)
#新房分支
# elif response.meta.get('text') == '新房':
# # 本分支需修改
# # item为LianjiaXinfangItem
# # 最终的解析页面需重设
# try:
# sum_ = response.xpath("""//*[@id="content"]/div[1]/div[@class="resultDes clear"]/h2/span/text()""").extract()[0].strip()
# except IndexError as e:
# logging.warning(e)
# sum_ = ''
# if sum_ != '':
# if int(sum_) > 0:
# try:
# # 获取本页面每页数据条数
# s = len(response.xpath("""//*[@id="content"]/div[1]/ul/li/div[1]/div[1]/a/@href""").extract())
# except IndexError as e:
# logging.warning(e)
# # 计算本URL的页数
# s_page = (int(sum_) + s - 1) // s
# status = response.meta.get('status')
# # 如果不超过100,全交给parse_NextPage去翻页处理,否则看状态
# if s_page <= 100:
# self.parse_NextPage(response)
# elif s_page > 100:
# meta = {'city': response.meta.get('city'),
# 'status': response.meta.get('status')}
# if status == 1:
# yield scrapy.Request(response.url, meta=meta,
# callback=self.pase_City) # 该种再次发送请求的方式逻辑上导致请求次数剧增,增加了爬取时间,但是这种方式同样会导致阻塞
# # self.pase_City(response)#该种调用方式由于造成循环调用,导致队列阻塞
# elif status == 2:
# yield scrapy.Request(response.url, meta=meta, callback=self.pase_Region)
# # self.pase_Region(response)
# elif status == 3:
# yield scrapy.Request(response.url, meta=meta, callback=self.parse_County)
# # self.parse_County(response)
# elif status == 4:
# with open('gt100.txt', 'a', newline='\n', encoding='utf-8') as f:
# f.write(response.url)
#二手房分支解析
# 解析页面,实现二手房分支的翻页,将翻页后的页面交给parse_ErshoufangEntry处理
def parse_ErshoufangNextPage(self, response):
meta = {'city': response.meta.get('city')}
s_page = response.meta.get('s_page')
for page in range(1, s_page+1):
url = response.url+'pg'+str(page)
yield scrapy.Request(url, meta=meta, callback=self.parse_ErshoufangEntry)
#解析二手房的详情链接
def parse_ErshoufangEntry(self, response):
meta = {'city': response.meta.get('city')}
details_href_list = response.xpath("""//*[@id="content"]/div[1]/ul/li/div[1]/div[1]/a/@href""").extract()
for href in details_href_list:
yield scrapy.Request(href, meta=meta, callback=self.parseErshoufangHTML)
#解析每一套房的详情页,并yield item
def parseErshoufangHTML(self, response):
item = LianjiaErshoufangItem()
item['city'] = response.meta.get('city')
#item['img_src'] = response.xpath('''//*[@id="topImg"]//div[@class="imgContainer"]/img/@src''').extract_first()
item['img_src'] = 'https://image1.ljcdn.com/110000-inspection/426839aeebee1c89ae14893cc19a1777-024.jpg.710x400.jpg'
item['region'] = response.xpath('''//div[@class="areaName"]/span[2]/a[1]/text()''').extract_first()
item['country'] = response.xpath('''//div[@class="areaName"]/span[2]/a[2]/text()''').extract_first()
item['title'] = response.xpath('''//div[@class='content']/div[@class='title']/h1/text()''').extract_first()
#price单价单位:元/平方米
item['price'] = response.xpath('''//div[@class='overview']/div[@class="content"]//div[@class="price "]//*[@class="unitPriceValue"]/text()''').extract_first()
#totalPrice总价单位:万元
item['totalPrice'] = response.xpath('''//div[@class='overview']/div[@class="content"]//div[@class="price "]/span/text()''').extract_first()
item['yrb'] = response.xpath('''//div[@class='area']/div[@class='subInfo']/text()''').extract_first()
#基本属性
base_xpath = response.xpath('''//*[@id="introduction"]/div/div/div[1]/div[2]/ul''')
item['layout'] = base_xpath.xpath('''./li[1]/text()''').extract_first()
item['floor'] = base_xpath.xpath('''./li[2]/text()''').extract_first()
item['acreage'] = base_xpath.xpath('''./li[3]/text()''').extract_first()
item['structureLayout'] = base_xpath.xpath('''./li[4]/text()''').extract_first()
item['inAcreage'] = base_xpath.xpath('''./li[5]/text()''').extract_first()
item['architectureType'] = base_xpath.xpath('''./li[6]/text()''').extract_first()
item['orientation'] = base_xpath.xpath('''./li[7]/text()''').extract_first()
item['buildingStructure'] = base_xpath.xpath('''./li[8]/text()''').extract_first()
item['decorationSituation'] = base_xpath.xpath('''./li[9]/text()''').extract_first()
item['thRatio'] = base_xpath.xpath('''./li[10]/text()''').extract_first()
item['elevator'] = base_xpath.xpath('''./li[11]/text()''').extract_first()
item['propertyRightYears'] = base_xpath.xpath('''./li[12]/text()''').extract_first()
#交易属性
business_xpath = response.xpath("""//*[@id="introduction"]/div/div/div[2]/div[2]/ul""")
item['listingTime'] = business_xpath.xpath("""./li[1]/span[2]/text()""").extract_first()
item['tradingRight'] = business_xpath.xpath("""./li[2]/span[2]/text()""").extract_first()
item['lastTransaction'] = business_xpath.xpath("""./li[3]/span[2]/text()""").extract_first()
item['housingUse'] = business_xpath.xpath("""./li[4]/span[2]/text()""").extract_first()
item['housingLife'] = business_xpath.xpath("""./li[5]/span[2]/text()""").extract_first()
item['propertyOwnership'] = business_xpath.xpath("""./li[6]/span[2]/text()""").extract_first()
item['mortgageInformation'] = business_xpath.xpath("""./li[7]/span[2]/@title""").extract_first()
item['housingSpareParts'] = business_xpath.xpath("""./li[8]/span[2]/text()""").extract_first()
# item['housingSocietyEncoding'] = business_xpath.xpath("""./li[9]/span[2]/text()""").extract_first()
yield(item)
能看一下你的def start_request() 吗??