BS对象使用string提取文字,提取不出来
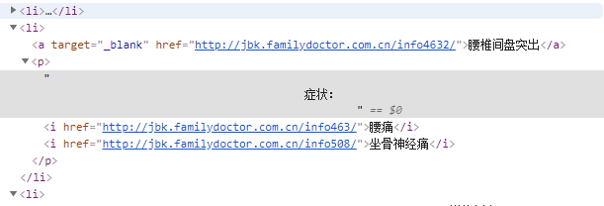
这个 【症状】前后有很多 tab空格,然后使用string无法提取出来【症状】二字,如何处理?
我使用的是text强行提取的,但是这样把后面【腰痛】【坐骨神经痛】就一起抽出来了,感觉不标准,如何优雅的把 【症状】二字给提取出来。
参考GPT和自己的思路:
针对这个问题,可以考虑先使用正则表达式来匹配字符串中的【症状】。由于字符串中有很多tab空格,这可能会导致匹配失败。可以先将字符串中的空白字符(包括空格、tab等)去掉。然后再使用正则表达式匹配。
示例代码如下:
import re
# 去掉字符串中的空白字符
text = " 【症状】腰痛、坐骨神经痛"
text = re.sub(r'\s', '', text)
# 使用正则表达式匹配 【症状】
match = re.search(r'【症状】', text)
if match:
print(match.group(0))
输出:
【症状】
这样就可以轻松地提取出【症状】了。如果想要提取出整个症状列表,可以根据匹配到的【症状】的位置来截取字符串,例如:
# 根据【症状】的位置截取症状列表
symptoms = text[match.end():]
print(symptoms)
输出:
腰痛、坐骨神经痛
这样就可以得到症状列表了。需要注意的是,如果症状列表中也包含了类似的【症状】之类的关键字,可能会导致匹配错误。这时需要根据实际情况进行调整。