爬取网易新闻首页广告图片超链接,输出一直为空。
from requests_html import HTMLSession
session = HTMLSession()
url = 'https://news.163.com/'
r = session.get(url)
print(r.html.text)
r.html.links
sel='//*[@id="index2016_wrap"]/div[1]/div[2]/div[2]/div[1]/div/iframe/html/body/a'
results = r.html.xpath(sel)
//这里也试过使用selector,调用html.find(),但是输出也是空
print(results)
https://news.163.com/
网上查了以后发现可能是因为直接从谷歌浏览器复制的selector、xpath和爬虫爬到的不一样。有没有解决这个问题的方法呢?
也有尝试过想用正则表达式,但是实在看不懂。
要爬取的是网易新闻首页广告的超链接。不知道为什么在图片上html代码最上面标签为iframe的那一行复制出来的路径是绝对路径,再往下就是相对路径了。我直接在标签为a的那行复制出来的是body>a。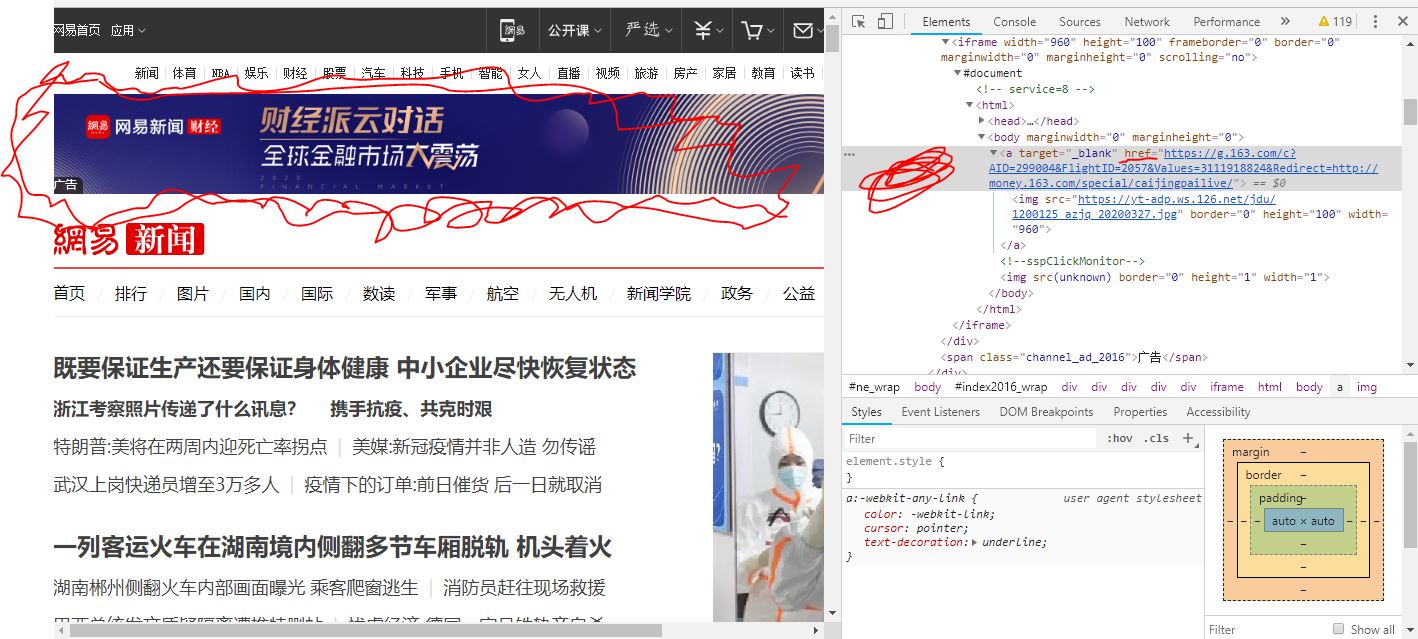
参考GPT和自己的思路:
首先,使用复制出来的selector和xpath可能会因为网页结构变动而失效,所以最好手动编写。其次,该页面的广告很可能是通过JS动态加载的,所以需要等待页面加载完成后再尝试爬取。
以下是一个可以爬取页面广告链接的示例代码:
```
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
使用selenium打开页面
url = 'https://n/